本文已於2014/02/12更新第二版,請參考人生說明書 v2。
人生Online Live
單一伺服器 現實世界版
全球7173476400人同時在線
全球7173476400人同時在線
前言
看標題會讓人一頭霧水,但這篇文章的目的非常簡單,就是說明什麼是人生。文內有一些數學計算、部分的定義及白話的文字說明,公式的部分希望有興趣的人能慢慢細讀,結論部分繁雜但可能有助理解全文。敬請指教。
遊戲簡介
這是一個比線上遊戲還殘酷的真實遊戲,在這遊戲中,輸了不一定是死了;死了也不一定輸了。每個玩家控制亦代表一個人,每個人擁有需要自行摸索的能力、長處與缺陷。
這個遊戲可能是個陣營遊戲,也可能是個單挑遊戲,屬於即時策略遊戲,亦不排除格鬥場景。考驗的是駕駛者的智力、反應力、靈敏度、策略設計、計算能力、學習能力、社交能力等全方位能力。
遊戲目的
在遊戲的不同階段,每個人的目的也不同。大致上來說,玩家可以同時達成、訂立多個目標,而最基本的目的則是安全存活。
其他常見的目的如:得到安定生活、成家立業、生兒育女、家財萬貫、受人景仰等等。簡而言之,玩家可以自訂想要的目的,也能隨時改變。
註:雖基本目的通常是存活,但仍有例外情形可以放棄此目標。
勝利方式
遊戲的勝利方式不受玩家訂定的目標所影響,因為這是個無法勝利的遊戲。
遊戲初始配件
- 人體(可能有所缺陷)。
- 家庭(可能有所缺陷)及其附件如:家產、前輩經驗知識。
遊戲回合
通常定一年為一回合,因為在這個遊戲中,每人所擁有的條件都是不相同的,唯一相同的條件就是每天都是二十四小時,遺憾的是,每人回合數仍然是不相同的。
計分方式
在人生中,所有行為皆有其價值,有些是立即性的報酬,有些可能是持續性的投資。而所謂的行為,包含動作、思考或任何不屬於以上兩者的耗時行動。只要是耗時行動,在人生中就是可評估、有其價值的。
任何行為的價值,並非由特定一或多人決定,計算出的結果也不是永久不變的。
行為價值
為衡量玩家在遊戲中的人生價值,因此需要將玩家所有行為的價值量化。根據玩家對於自己與他人所認為的重要程度進行加權平均,公式如下:
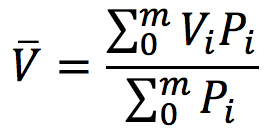
其中:V表示所有人對此人的加權平均評價,Vi表示第i人對此人此行為評價,Pi表示第i人對此人的重要性加權,m表示總人數。
舉例
某人拾金不昧,他本人認為此行為價值V0=105,他的情人認為此行為價值V1=110,所有其他人認為此行為V2~m=100。他較在意他情人對他的看法,因此情人加權為P1=2倍,他較不在意他人對他的看法,因此他人加權為P2~m=0.9,本人為P0=1。
拾金不昧行為價值=(105*1+110*2+100*0.9)/(1+2+0.9)=106.41。
註:以上皆為他本人的觀察角度,因為此遊戲無法獲勝,雖在計算中要考慮別人的看法,但實際觀察角度永遠以自身為準。
行為期望值
玩家在面臨選擇時大多依賴期望值作出選擇,而期望值則由作出選擇後可能發生的情形的代價乘上發生機率加總。
註:行為期望值與行為價值的不同之處為行為期望值只適用於行動前的評估,而行動後只需使用行為價值做計算。因此可能行為期望值極高,結果行為價值極低。
人生價值
有些人認為,在人生結束之時,便是結算點;有些人認為,在壯年時期事業最高峰,才是結算點。而結算角度雖皆從自身出發,但仍須考慮其他人對其的加權。
詳細計算過程為:
1. 設定結算時段[0, T]。
2. 將結算時段分割成n等分,第i等分t=iT/n。
3. 計算出t瞬間所有人對此人的加權平均評價V(t)。
4. 將所有瞬間的V(t)以不同時間做加權平均。
因此公式如下:
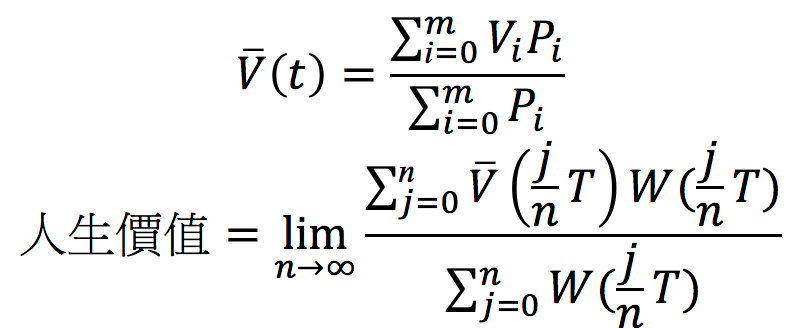
其中:V(t) 表示在時刻t所有人對此人的加權平均評價,Vi表示第i人對此人評價,Pi表示某人對此人的重要性加權,m表示總人數。W表示某瞬間的時間重要性加權,T是結算終點,n表示將此時段[0, T]分割成n等分。
舉例
某人將人生分成三段計算:青年、壯年、老年,其中他特別在意壯年時期在他整體人生中的重要性,其次是老年,因此他的時間重要性加權分別1,1.5,1.2。而在這三段時期內,他本人對於他的評價分別是100,150,80,他本人的重要性加權為1。他的伴侶對他的評價分別是120,130,80,伴侶對他的重要性加權為1.2。他的家人對他的評價分別是100,200,80,家人的重要性加權為0.9,忽略剩餘的其他人,假設他的壽命為100歲亦訂為結算終點。
表格整理如下:
|
n=3
|
|
青年
|
壯年
|
老年
|
|
|
|
W(100/3)=1
|
W(200/3)=1.5
|
W(300/3)=1.2
|
|
本人
|
P0=1
|
100
|
150
|
80
|
|
伴侶
|
P1=1.2
|
120
|
130
|
80
|
|
家人
|
P2=0.9
|
100
|
200
|
80
|
人生價值計算:

故假如此人的評分標準足夠客觀,且以所有人平均值為100,此人人生價值為118.62,高於100,便可說此人擁有成功的人生。
註:亦可說成功的人生定義為人生價值大於100。這樣的觀點仍是來自於他本人,正因如此,這是個無法勝利的遊戲。有可能所有人都認為他是個失敗的人生,只有他自己評價成功,但事實成功於否無法論定。
結論
若單純只是看內容,應該很難理解在講什麼,有時候我們會想,到底怎樣是成功,家財萬貫、成家立業,好像都符合大家的期望,但有些人默默無名,依然活得很快樂,難道是快樂第一嗎?事實上,滿足快樂只是一部分的慾望,這端看一個人認定的目標為何。在這篇文章中,我直接省略其他角度的觀點,因為深入的討論這個是沒有意義的,畢竟這個遊戲永遠無法獲勝,所以重點鎖定在一個人對自己的看法,但又不能排除其他人對自己的看法,所以出現加權平均,特別的是加權的量也是由自己所掌控的。我們可以把這當做對人生的體悟,如果想通了、也認同這樣的說法,可以說人生已經無所失亦無所得了。
而可以注意到,我在文中時常強調這是個無法獲勝的遊戲,這省去很多計算及定義的麻煩,如果這是個可以獲勝的遊戲,那肯定的是獲勝的方式還是未知的,例如:得到某稀世珍寶、找到One Piece。但這同時也是所有人嚮往的目標,理由很簡單,就是這遊戲無法獲勝,但大家依然想贏。
當然了,在現實生活中,我們很難準確地一一量化所有數值,但這不表示這些公式都是沒有意義的,這提供了自己行事的一些參考依據,例如說,當我們不知如何做決定時,可以依照期望值作出選擇,事後也可以計算行為價值來檢討反省,而人生價值更是最重要的,假如所有人一輩子能做的事情一樣多,一個人不斷選擇行為期望值高的來做,他的人生價值基本上就會是較高的。而例外發生在,他在中途改變目標,也就是在不同時刻他對同一件事的評價改變,換句話說,一個人堅持目標,並選擇期望值最高的事來做,理論上會是最成功人生,這也和許多人的人生經歷不謀而合。
後記
感覺還有很多可以補充的,但這幾個基本論點應該已經算完備,一開始是想要把人生價值用積分的形態來表現,但後來發現只有概念類似,計算過程是不太一樣的。
我不能否認這是個人觀點,但我認為,可以把所有人對於人生的理解套入我的理解內,那我的說明就是客觀且足以成為標準的。
無論如何,還是希望能看到任何意見,甚至是不同版本的人生說明書。