Installation
!pip install TEF -U
import TEF
TEF.__version__
'0.7.7'
!pip install TEF -U
import TEF
TEF.__version__
'0.7.7'
import pandas as pd
train_transaction_raw = pd.read_csv('data/ieee-fraud-detection.zip Folder/train_transaction.csv')
import TEF
train_transaction = TEF.auto_set_dtypes(train_transaction_raw, set_object=[0])
TEF.dfmeta(train_transaction)
TEF.plot_1var(train_transaction)
TEF.plot_1var_by_cat_y(train_transaction, 'isFraud')
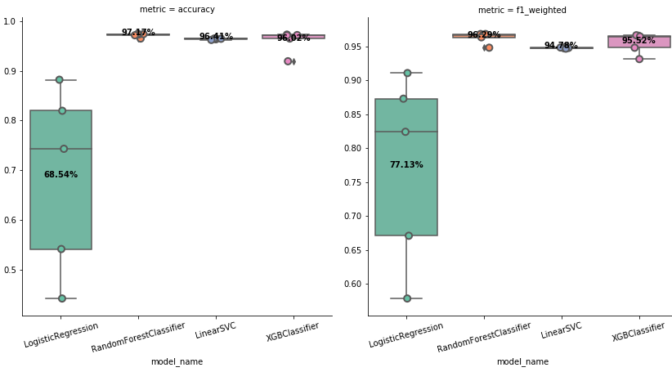
TEF.fit(train_transaction, 'isFraud', verbose=2)
Disclaimer and Caveat
Every ML practitioner knows it is a risky behavior to fit a model without understanding the data. The purpose of this article is to introduce the universal usage of TEF only instead of detailed exploration. Within these code, we can only have a rough understanding about the dataset.
In the following section I will walk through these codes for this ieee fraud detection dataset. A more detailed exploration, feature engineering, and model selection may be published in the future.
Continue reading How To Fit A Machine Learning Model To A Kaggle Dataset In 8 Lines