Installation
!pip install TEF -U
import TEF
TEF.__version__
'0.7.7'Load dataset
titanic_raw = TEF.load_dataset('titanic_raw')
This famous dataset is merged from Kaggle and seaborn.
We usually start from head(), but is it possible to understand a dataset with only 6 rows?
titanic_raw.head()
| survived | passenger_id | name | pclass | age | birth | sibsp | parch | fare | who | deck | embark_town | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | False | 1 | Braund, Mr. Owen Harris | 3 | 22 | 1890-04-19 | 1 | 0 | 7.25 | man | nan | Southampton | False |
| 1 | True | 2 | Cumings, Mrs. John Bradley (Florence Briggs Thayer) | 1 | 38 | 1874-04-23 | 1 | 0 | 71.2833 | woman | C | Cherbourg | False |
| 2 | True | 3 | Heikkinen, Miss. Laina | 3 | 26 | 1886-04-20 | 0 | 0 | 7.925 | woman | nan | Southampton | True |
| 3 | True | 4 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | 1 | 35 | 1877-04-22 | 1 | 0 | 53.1 | woman | C | Southampton | False |
| 4 | False | 5 | Allen, Mr. William Henry | 3 | 35 | 1877-04-22 | 0 | 0 | 8.05 | man | nan | Southampton | True |
Set dtypes
titanic = TEF.auto_set_dtypes(titanic_raw)
before dtypes: bool(2), float64(2), int64(4), object(5)
after dtypes: bool(2), category(3), datetime64[ns](1), float64(2), int64(4), object(1)
possible identifier cols: 1 passenger_id
consider using set_object=[1]
possible category cols: 3 pclass (3 levls), 6 sibsp (7 levls), 7 parch (7 levls)
consider using set_category=[3, 6, 7]If you accept the suggestion,
titanic = TEF.auto_set_dtypes(titanic_raw, set_object=[1], verbose=0)
Generating metadata
Just pass any dataset you are working on to TEF.dfmeta.
TEF.dfmeta(titanic)
| col name | idx | dtype | NaNs | unique counts | summary | summary plot | possible NaNs | possible dup lev | row 21 | row 35 | row 605 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| survived | 0 | bool | 0 0% |
2 0% |
False 62% True 38% |
 |
True | False | False | ||
| passenger_id | 1 | object | 0 0% |
891 100% |
other 100% |  |
22 | 36 | 606 | ||
| name | 2 | object | 0 0% |
891 100% |
other 100% |  |
Beesley, Mr. Lawrence | Holverson, Mr. Alexander Oskar | Lindell, Mr. Edvard Bengtsson | ||
| pclass | 3 | int64 | 0 0% |
3 0% |
3 55% 1 24% 2 21% |
 |
2 | 1 | 3 | ||
| age | 4 | float64 | 177 20% |
89 10% |
[0.42, 20.125, 28.0, 38.0, 80.0] mean: 29.70 std: 14.53 cv: 0.49 skew: 0.39* log skew: -2.30 |
 |
34 | 42 | 36 | ||
| birth | 5 | datetime64[ns] | 177 20% |
72 8% |
1832-05-03 1874-04-23 1884-04-20 1892-04-18 1912-04-14 |
 |
1878-04-22 00:00:00 | 1870-04-24 00:00:00 | 1876-04-22 00:00:00 | ||
| sibsp | 6 | int64 | 0 0% |
7 1% |
[0.0, 0.0, 0.0, 1.0, 8.0] mean: 0.52 std: 1.10 cv: 2.11 skew: 3.69* log skew: 1.67 |
 |
0 | 1 | 1 | ||
| parch | 7 | int64 | 0 0% |
7 1% |
[0.0, 0.0, 0.0, 0.0, 6.0] mean: 0.38 std: 0.81 cv: 2.11 skew: 2.74* log skew: 0.93 |
 |
0 | 0 | 0 | ||
| fare | 8 | float64 | 0 0% |
248 28% |
[0.0, 7.9104, 14.4542, 31.0, 512.3292] mean: 32.20 std: 49.69 cv: 1.54 skew: 4.78* log skew: 0.90 |
 |
13 | 52 | 15.55 | ||
| who | 9 | category | 0 0% |
3 0% |
man 60% woman 30% child 9% |
 |
(man, woman) | man | man | man | |
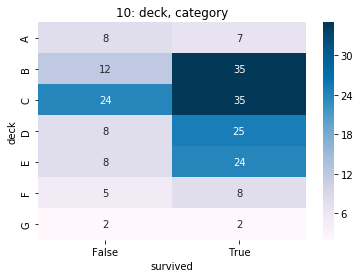
| deck | 10 | category | 688 77% |
8 1% |
nan 77% C 7% B 5% D 4% E 4% A 2% F 1% G 0% |
 |
D | nan | nan | ||
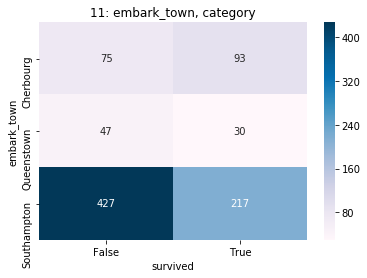
| embark_town | 11 | category | 2 0% |
4 0% |
Southampton 72% Cherbourg 19% Queenstown 9% nan 0% |
 |
Southampton | Southampton | Southampton | ||
| alone | 12 | bool | 0 0% |
2 0% |
True 60% False 40% |
 |
True | False | False |
Have a description dictionary prepared and start filling it in.
TEF.get_desc_template(titanic)
desc = {
"survived" : "",
"passenger_id": "",
"name" : "",
"pclass" : "",
"age" : "",
"birth" : "",
"sibsp" : "",
"parch" : "",
"fare" : "",
"who" : "",
"deck" : "",
"embark_town" : "",
"alone" : ""
}
Or, I personally like a separate file so that I can fill it in another window.
TEF.get_desc_template_file(titanic)
'desc.py saved'
Use %run desc.py to load it back on jupyter notebook. But here we will use inline desc for the sake of demo.
And call TEF.dfmeta again. Now you will have a column explaining the data.
desc = {
"survived" : "Survived (1) or died (0)",
"passenger_id": "Unique ID of the passenger",
"name" : "Passenger's name",
"pclass" : "Passenger's class (1st, 2nd, or 3rd)",
"age" : "Passenger's age",
"birth" : "Created from minusing the titanic happened date from Age",
"sibsp" : "Number of siblings/spouses aboard the Titanic",
"parch" : "Number of parents/children aboard the Titanic",
"fare" : "Fare paid for ticket",
"who" : "Whether the passenger is man, woman, or child",
"deck" : "",
"embark_town" : "Where the passenger got on the ship (C - Cherbourg, S - Southampton, Q = Queenstown)",
"alone" : ""
}
TEF.dfmeta(titanic, description=desc)
| col name | idx | dtype | description | NaNs | unique counts | summary | summary plot | possible NaNs | possible dup lev | row 304 | row 629 | row 680 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| survived | 0 | bool | Survived (1) or died (0) | 0 0% |
2 0% |
False 62% True 38% |
|
False | False | False | ||
| passenger_id | 1 | object | Unique ID of the passenger | 0 0% |
891 100% |
other 100% | |
305 | 630 | 681 | ||
| name | 2 | object | Passenger’s name | 0 0% |
891 100% |
other 100% | |
Williams, Mr. Howard Hugh “Harry” | O’Connell, Mr. Patrick D | Peters, Miss. Katie | ||
| pclass | 3 | int64 | Passenger’s class (1st, 2nd, or 3rd) | 0 0% |
3 0% |
3 55% 1 24% 2 21% |
|
3 | 3 | 3 | ||
| age | 4 | float64 | Passenger’s age | 177 20% |
89 10% |
[0.42, 20.125, 28.0, 38.0, 80.0] mean: 29.70 std: 14.53 cv: 0.49 skew: 0.39* log skew: -2.30 |
|
nan | nan | nan | ||
| birth | 5 | datetime64[ns] | Created from minusing the titanic happened date from Age | 177 20% |
72 8% |
1832-05-03 1874-04-23 1884-04-20 1892-04-18 1912-04-14 |
|
nan | nan | nan | ||
| sibsp | 6 | int64 | Number of siblings/spouses aboard the Titanic | 0 0% |
7 1% |
[0.0, 0.0, 0.0, 1.0, 8.0] mean: 0.52 std: 1.10 cv: 2.11 skew: 3.69* log skew: 1.67 |
|
0 | 0 | 0 | ||
| parch | 7 | int64 | Number of parents/children aboard the Titanic | 0 0% |
7 1% |
[0.0, 0.0, 0.0, 0.0, 6.0] mean: 0.38 std: 0.81 cv: 2.11 skew: 2.74* log skew: 0.93 |
|
0 | 0 | 0 | ||
| fare | 8 | float64 | Fare paid for ticket | 0 0% |
248 28% |
[0.0, 7.9104, 14.4542, 31.0, 512.3292] mean: 32.20 std: 49.69 cv: 1.54 skew: 4.78* log skew: 0.90 |
|
8.05 | 7.7333 | 8.1375 | ||
| who | 9 | category | Whether the passenger is man, woman, or child | 0 0% |
3 0% |
man 60% woman 30% child 9% |
|
(man, woman) | man | man | woman | |
| deck | 10 | category | 688 77% |
8 1% |
nan 77% C 7% B 5% D 4% E 4% A 2% F 1% G 0% |
|
nan | nan | nan | |||
| embark_town | 11 | category | Where the passenger got on the ship (C – Cherbourg, S – Southampton, Q = Queenstown) | 2 0% |
4 0% |
Southampton 72% Cherbourg 19% Queenstown 9% nan 0% |
|
Southampton | Queenstown | Queenstown | ||
| alone | 12 | bool | 0 0% |
2 0% |
True 60% False 40% |
|
True | True | True |
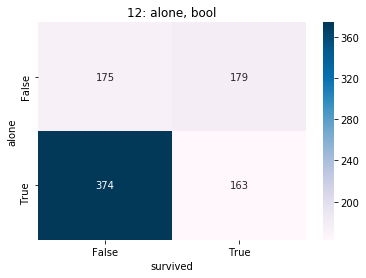
See the relations between target and variables
TEF.plot_1var_by_cat_y(titanic, 'survived')
1, passenger_id, object, has 891 levels, skipped plotting
2, name, object, has 891 levels, skipped plotting
NaNs: 0
NaNs: 19.87%
5 not yet for datetime
NaNs: 0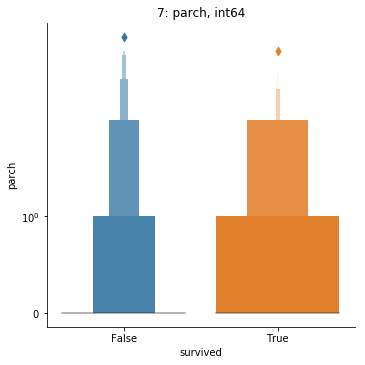
NaNs: 0
NaNs: 0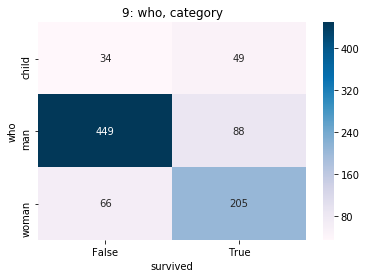
Fit models
Now fit default classification models with one line.
TEF.fit(titanic, 'survived')
original X:
shape: (891, 12)
dtypes: bool(1), category(3), datetime64[ns](1), float64(2), int64(3), object(2)
processed X:
shape: (891, 13)
dtypes: bool(1), category(3), float64(6), int64(3)
y: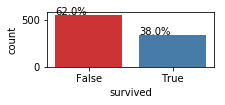
dummy X:
shape: (891, 23)
dtypes: bool(1), float64(6), int64(3), uint8(13)
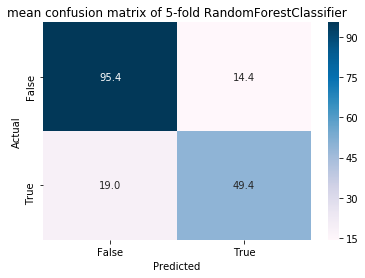
classification result:
accuracy : 81.26
false positive: 8.08
false negative: 10.66
f1 : 74.74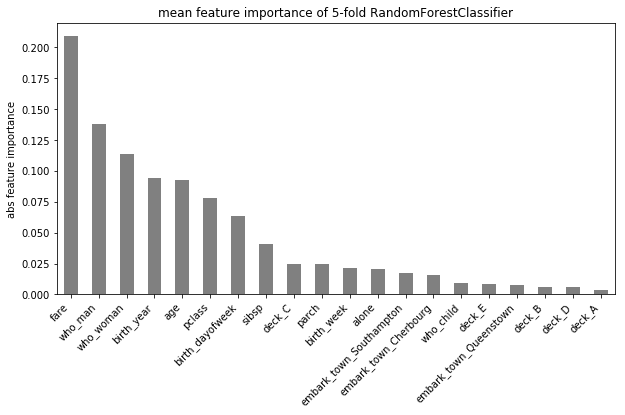
Put fitted feature importance into dfmeta
If it looks okay, you can save the feature importance and pass it to dfmeta to have another column. Or you can train your own model and pass the feature importance here.
feat_imp = TEF.fit(titanic, 'survived', verbose=0, return_agg_feat_imp=True)
TEF.dfmeta(titanic, description=desc, fitted_feat_imp=feat_imp)
| col name | idx | dtype | description | NaNs | unique counts | summary | summary plot | fitted feature importance | possible NaNs | possible dup lev | row 158 | row 173 | row 790 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| survived | 0 | bool | Survived (1) or died (0) | 0 0% |
2 0% |
False 62% True 38% |
|
False | False | False | |||
| passenger_id | 1 | object | Unique ID of the passenger | 0 0% |
891 100% |
other 100% | |
159 | 174 | 791 | |||
| name | 2 | object | Passenger’s name | 0 0% |
891 100% |
other 100% | |
Smiljanic, Mr. Mile | Sivola, Mr. Antti Wilhelm | Keane, Mr. Andrew “Andy” | |||
| pclass | 3 | int64 | Passenger’s class (1st, 2nd, or 3rd) | 0 0% |
3 0% |
3 55% 1 24% 2 21% |
|
2/10 0.24 27% | 3 | 3 | 3 | ||
| age | 4 | float64 | Passenger’s age | 177 20% |
89 10% |
[0.42, 20.125, 28.0, 38.0, 80.0] mean: 29.70 std: 14.53 cv: 0.49 skew: 0.39* log skew: -2.30 |
|
7/10 0.02 3% | nan | 21 | nan | ||
| birth | 5 | datetime64[ns] | Created from minusing the titanic happened date from Age | 177 20% |
72 8% |
1832-05-03 1874-04-23 1884-04-20 1892-04-18 1912-04-14 |
|
8/10 0.02 2% | NaT | 1891-04-19 00:00:00 | NaT | ||
| sibsp | 6 | int64 | Number of siblings/spouses aboard the Titanic | 0 0% |
7 1% |
[0.0, 0.0, 0.0, 1.0, 8.0] mean: 0.52 std: 1.10 cv: 2.11 skew: 3.69* log skew: 1.67 |
|
6/10 0.02 3% | 0 | 0 | 0 | ||
| parch | 7 | int64 | Number of parents/children aboard the Titanic | 0 0% |
7 1% |
[0.0, 0.0, 0.0, 0.0, 6.0] mean: 0.38 std: 0.81 cv: 2.11 skew: 2.74* log skew: 0.93 |
|
9/10 0.02 2% | 0 | 0 | 0 | ||
| fare | 8 | float64 | Fare paid for ticket | 0 0% |
248 28% |
[0.0, 7.9104, 14.4542, 31.0, 512.3292] mean: 32.20 std: 49.69 cv: 1.54 skew: 4.78* log skew: 0.90 |
|
4/10 0.03 4% | 8.6625 | 7.925 | 7.75 | ||
| who | 9 | category | Whether the passenger is man, woman, or child | 0 0% |
3 0% |
man 60% woman 30% child 9% |
|
1/10 0.44 49% | (man, woman) | man | man | man | |
| deck | 10 | category | 688 77% |
8 1% |
nan 77% C 7% B 5% D 4% E 4% A 2% F 1% G 0% |
|
3/10 0.05 5% | nan | nan | nan | |||
| embark_town | 11 | category | Where the passenger got on the ship (C – Cherbourg, S – Southampton, Q = Queenstown) | 2 0% |
4 0% |
Southampton 72% Cherbourg 19% Queenstown 9% nan 0% |
|
5/10 0.03 3% | Southampton | Southampton | Queenstown | ||
| alone | 12 | bool | 0 0% |
2 0% |
True 60% False 40% |
|
10/10 0.01 2% | True | True | True |
Standardize metadata
After you clean and look into those dirty values, you probably don’t need “possible NaNs”, “possible dub lev” and those samples there. Add another argument stadard=True to remove them and generate the final standardize metadata.
meta = TEF.dfmeta(titanic, description=desc, fitted_feat_imp=feat_imp, standard=True)
meta
| col name | idx | dtype | description | NaNs | unique counts | summary | summary plot | fitted feature importance |
|---|---|---|---|---|---|---|---|---|
| survived | 0 | bool | Survived (1) or died (0) | 0 0% |
2 0% |
False 62% True 38% |
|
|
| passenger_id | 1 | object | Unique ID of the passenger | 0 0% |
891 100% |
other 100% | |
|
| name | 2 | object | Passenger’s name | 0 0% |
891 100% |
other 100% | |
|
| pclass | 3 | int64 | Passenger’s class (1st, 2nd, or 3rd) | 0 0% |
3 0% |
3 55% 1 24% 2 21% |
|
2/10 0.24 27% |
| age | 4 | float64 | Passenger’s age | 177 20% |
89 10% |
[0.42, 20.125, 28.0, 38.0, 80.0] mean: 29.70 std: 14.53 cv: 0.49 skew: 0.39* log skew: -2.30 |
|
7/10 0.02 3% |
| birth | 5 | datetime64[ns] | Created from minusing the titanic happened date from Age | 177 20% |
72 8% |
1832-05-03 1874-04-23 1884-04-20 1892-04-18 1912-04-14 |
|
8/10 0.02 2% |
| sibsp | 6 | int64 | Number of siblings/spouses aboard the Titanic | 0 0% |
7 1% |
[0.0, 0.0, 0.0, 1.0, 8.0] mean: 0.52 std: 1.10 cv: 2.11 skew: 3.69* log skew: 1.67 |
|
6/10 0.02 3% |
| parch | 7 | int64 | Number of parents/children aboard the Titanic | 0 0% |
7 1% |
[0.0, 0.0, 0.0, 0.0, 6.0] mean: 0.38 std: 0.81 cv: 2.11 skew: 2.74* log skew: 0.93 |
|
9/10 0.02 2% |
| fare | 8 | float64 | Fare paid for ticket | 0 0% |
248 28% |
[0.0, 7.9104, 14.4542, 31.0, 512.3292] mean: 32.20 std: 49.69 cv: 1.54 skew: 4.78* log skew: 0.90 |
|
4/10 0.03 4% |
| who | 9 | category | Whether the passenger is man, woman, or child | 0 0% |
3 0% |
man 60% woman 30% child 9% |
|
1/10 0.44 49% |
| deck | 10 | category | 688 77% |
8 1% |
nan 77% C 7% B 5% D 4% E 4% A 2% F 1% G 0% |
|
3/10 0.05 5% | |
| embark_town | 11 | category | Where the passenger got on the ship (C – Cherbourg, S – Southampton, Q = Queenstown) | 2 0% |
4 0% |
Southampton 72% Cherbourg 19% Queenstown 9% nan 0% |
|
5/10 0.03 3% |
| alone | 12 | bool | 0 0% |
2 0% |
True 60% False 40% |
|
10/10 0.01 2% |
Generate a final metadata
Now everything is clean and neat. You can export it to a HTML file. So that you can distribute it or just open it in another window while you are doing more stuff.
TEF.dfmeta_to_htmlfile(meta, filename='titanic_dfmeta.html', head='titanic metadata')
'titanic_dfmeta.html saved'Or if you want the source HTML code to paste it somewhere.
print(meta.data)
<style type="text/css" >
#T_069198c8_cfa6_11e9_9138_5c5f67a418f1row0_col0 {
background-color: white;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row0_col1 {
border: 1px solid white;
background-color: #e7fefe;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row0_col2 {
border: 1px solid white;
background-color: #e7fefe;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row0_col3 {
border: 1px solid white;
background-color: #e7fefe;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row0_col4 {
border: 1px solid white;
background-color: #e7fefe;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row0_col5 {
border: 1px solid white;
background-color: #e7fefe;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row0_col6 {
border: 1px solid white;
background-color: #e7fefe;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row0_col7 {
border: 1px solid white;
background-color: #e7fefe;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row0_col8 {
border: 1px solid white;
background-color: #e7fefe;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row1_col0 {
background-color: white;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row1_col1 {
border: 1px solid white;
background-color: #f2f2f2;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row1_col2 {
border: 1px solid white;
background-color: #f2f2f2;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row1_col3 {
border: 1px solid white;
background-color: #f2f2f2;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row1_col4 {
border: 1px solid white;
background-color: #f2f2f2;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row1_col5 {
border: 1px solid white;
background-color: #f2f2f2;
color: blue;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row1_col6 {
border: 1px solid white;
background-color: #f2f2f2;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row1_col7 {
border: 1px solid white;
background-color: #f2f2f2;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row1_col8 {
border: 1px solid white;
background-color: #f2f2f2;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row2_col0 {
background-color: white;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row2_col1 {
border: 1px solid white;
background-color: #f2f2f2;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row2_col2 {
border: 1px solid white;
background-color: #f2f2f2;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row2_col3 {
border: 1px solid white;
background-color: #f2f2f2;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row2_col4 {
border: 1px solid white;
background-color: #f2f2f2;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row2_col5 {
border: 1px solid white;
background-color: #f2f2f2;
color: blue;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row2_col6 {
border: 1px solid white;
background-color: #f2f2f2;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row2_col7 {
border: 1px solid white;
background-color: #f2f2f2;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row2_col8 {
border: 1px solid white;
background-color: #f2f2f2;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row3_col0 {
background-color: white;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row3_col1 {
border: 1px solid white;
background-color: #fefee7;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row3_col2 {
border: 1px solid white;
background-color: #fefee7;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row3_col3 {
border: 1px solid white;
background-color: #fefee7;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row3_col4 {
border: 1px solid white;
background-color: #fefee7;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row3_col5 {
border: 1px solid white;
background-color: #fefee7;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row3_col6 {
border: 1px solid white;
background-color: #fefee7;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row3_col7 {
border: 1px solid white;
background-color: #fefee7;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row3_col8 {
border: 1px solid white;
background-color: #fefee7;
font-weight: bold;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row4_col0 {
background-color: white;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row4_col1 {
border: 1px solid white;
background-color: #fef2e7;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row4_col2 {
border: 1px solid white;
background-color: #fef2e7;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row4_col3 {
border: 1px solid white;
background-color: #fef2e7;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row4_col4 {
border: 1px solid white;
background-color: #fef2e7;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row4_col5 {
border: 1px solid white;
background-color: #fef2e7;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row4_col6 {
border: 1px solid white;
background-color: #fef2e7;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row4_col7 {
border: 1px solid white;
background-color: #fef2e7;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row4_col8 {
border: 1px solid white;
background-color: #fef2e7;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row5_col0 {
background-color: white;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row5_col1 {
border: 1px solid white;
background-color: #e7feee;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row5_col2 {
border: 1px solid white;
background-color: #e7feee;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row5_col3 {
border: 1px solid white;
background-color: #e7feee;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row5_col4 {
border: 1px solid white;
background-color: #e7feee;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row5_col5 {
border: 1px solid white;
background-color: #e7feee;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row5_col6 {
border: 1px solid white;
background-color: #e7feee;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row5_col7 {
border: 1px solid white;
background-color: #e7feee;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row5_col8 {
border: 1px solid white;
background-color: #e7feee;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row6_col0 {
background-color: white;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row6_col1 {
border: 1px solid white;
background-color: #fefee7;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row6_col2 {
border: 1px solid white;
background-color: #fefee7;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row6_col3 {
border: 1px solid white;
background-color: #fefee7;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row6_col4 {
border: 1px solid white;
background-color: #fefee7;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row6_col5 {
border: 1px solid white;
background-color: #fefee7;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row6_col6 {
border: 1px solid white;
background-color: #fefee7;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row6_col7 {
border: 1px solid white;
background-color: #fefee7;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row6_col8 {
border: 1px solid white;
background-color: #fefee7;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row7_col0 {
background-color: white;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row7_col1 {
border: 1px solid white;
background-color: #fefee7;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row7_col2 {
border: 1px solid white;
background-color: #fefee7;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row7_col3 {
border: 1px solid white;
background-color: #fefee7;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row7_col4 {
border: 1px solid white;
background-color: #fefee7;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row7_col5 {
border: 1px solid white;
background-color: #fefee7;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row7_col6 {
border: 1px solid white;
background-color: #fefee7;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row7_col7 {
border: 1px solid white;
background-color: #fefee7;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row7_col8 {
border: 1px solid white;
background-color: #fefee7;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row8_col0 {
background-color: white;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row8_col1 {
border: 1px solid white;
background-color: #fef2e7;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row8_col2 {
border: 1px solid white;
background-color: #fef2e7;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row8_col3 {
border: 1px solid white;
background-color: #fef2e7;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row8_col4 {
border: 1px solid white;
background-color: #fef2e7;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row8_col5 {
border: 1px solid white;
background-color: #fef2e7;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row8_col6 {
border: 1px solid white;
background-color: #fef2e7;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row8_col7 {
border: 1px solid white;
background-color: #fef2e7;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row8_col8 {
border: 1px solid white;
background-color: #fef2e7;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row9_col0 {
background-color: white;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row9_col1 {
border: 1px solid white;
background-color: #e7ecfe;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row9_col2 {
border: 1px solid white;
background-color: #e7ecfe;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row9_col3 {
border: 1px solid white;
background-color: #e7ecfe;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row9_col4 {
border: 1px solid white;
background-color: #e7ecfe;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row9_col5 {
border: 1px solid white;
background-color: #e7ecfe;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row9_col6 {
border: 1px solid white;
background-color: #e7ecfe;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row9_col7 {
border: 1px solid white;
background-color: #e7ecfe;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row9_col8 {
border: 1px solid white;
background-color: #e7ecfe;
font-weight: bold;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row10_col0 {
background-color: white;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row10_col1 {
border: 1px solid white;
background-color: #e7ecfe;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row10_col2 {
border: 1px solid white;
background-color: #e7ecfe;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row10_col3 {
border: 1px solid white;
background-color: #e7ecfe;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row10_col4 {
border: 1px solid white;
background-color: #e7ecfe;
color: red;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row10_col5 {
border: 1px solid white;
background-color: #e7ecfe;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row10_col6 {
border: 1px solid white;
background-color: #e7ecfe;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row10_col7 {
border: 1px solid white;
background-color: #e7ecfe;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row10_col8 {
border: 1px solid white;
background-color: #e7ecfe;
font-weight: bold;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row11_col0 {
background-color: white;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row11_col1 {
border: 1px solid white;
background-color: #e7ecfe;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row11_col2 {
border: 1px solid white;
background-color: #e7ecfe;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row11_col3 {
border: 1px solid white;
background-color: #e7ecfe;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row11_col4 {
border: 1px solid white;
background-color: #e7ecfe;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row11_col5 {
border: 1px solid white;
background-color: #e7ecfe;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row11_col6 {
border: 1px solid white;
background-color: #e7ecfe;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row11_col7 {
border: 1px solid white;
background-color: #e7ecfe;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row11_col8 {
border: 1px solid white;
background-color: #e7ecfe;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row12_col0 {
background-color: white;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row12_col1 {
border: 1px solid white;
background-color: #e7fefe;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row12_col2 {
border: 1px solid white;
background-color: #e7fefe;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row12_col3 {
border: 1px solid white;
background-color: #e7fefe;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row12_col4 {
border: 1px solid white;
background-color: #e7fefe;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row12_col5 {
border: 1px solid white;
background-color: #e7fefe;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row12_col6 {
border: 1px solid white;
background-color: #e7fefe;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row12_col7 {
border: 1px solid white;
background-color: #e7fefe;
} #T_069198c8_cfa6_11e9_9138_5c5f67a418f1row12_col8 {
border: 1px solid white;
background-color: #e7fefe;
}</style><table id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1" ><caption>shape: (891, 13); dtypes: bool(2), category(3), datetime64[ns](1), float64(2), int64(3), object(2); memory usage: 60.7+ KB</caption><thead> <tr> <th class="col_heading level0 col0" >col name</th> <th class="col_heading level0 col1" >idx</th> <th class="col_heading level0 col2" >dtype</th> <th class="col_heading level0 col3" >description</th> <th class="col_heading level0 col4" >NaNs</th> <th class="col_heading level0 col5" >unique counts</th> <th class="col_heading level0 col6" >summary</th> <th class="col_heading level0 col7" >summary plot</th> <th class="col_heading level0 col8" >fitted feature importance</th> </tr></thead><tbody>
<tr>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row0_col0" class="data row0 col0" >survived</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row0_col1" class="data row0 col1" >0</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row0_col2" class="data row0 col2" >bool</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row0_col3" class="data row0 col3" >Survived (1) or died (0)</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row0_col4" class="data row0 col4" >0<br/> 0%</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row0_col5" class="data row0 col5" >2<br/> 0%</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row0_col6" class="data row0 col6" >False 62%<br/> True 38%</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row0_col7" class="data row0 col7" ><img src='data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAkAAAACQCAYAAADgO9QwAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADl0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uIDMuMC4zLCBodHRwOi8vbWF0cGxvdGxpYi5vcmcvnQurowAAC71JREFUeJzt3X/sXXV9x/HnixYQ5gAVWKCt0oxO1xlQ0nQws2WDGQsiJctYIAyJ4pptSHAsU5iTZEsgW0x0YtCkgAskMCQwpRoyx1CXuIRKKQrDDmlYsA1Op/LDDQYU3vvjfr7j2n4LbPK953vv5/lIbno+n/M5J+/zTU++r+/5nHNPqgpJkqSe7DN0AZIkSZNmAJIkSd0xAEmSpO4YgCRJUncMQJIkqTsGIEmS1B0DkCRJ6o4BSJIkdccAJEmSumMAkiRJ3TEASZKk7hiAJElSdwxAkiSpOwYgAZDkkCQ3J/nXJNuSnJDko619b5LPJTlkL9uuS/JAku1JLh7rv75te/lY30eSrJ/EMUmStDcGIM35BPD3VfUm4FhgG3A78OaqOgb4NnDJ7hslWQJcCZwMrAbOSrI6yTEAbdtfTXJwkiOAtVV160SOSJKkvTAAiSQHAb8GXANQVc9U1WNV9Q9VtasNuxNYPs/ma4HtVfVQVT0D3AisB54FDkiyD7Af8BzwF8ClC3s0kiS9tFTV0DUsakn+A3h46DoW2AHAUcBTwIHAfwE7gOfHxhwN/Kh9xr0GOIgXfkavBV4NfAdYAfws8EPgCeBwZv9nKUnT7g1VddjQRSy0pUMXMAUerqo1QxexkJKsYXSF58Sq2pzkE8ATVfWRtv7DwBrgt2q3xJzkDOAdVfW+1j6H0TTXBbuN+wLwduA9jKbYbq+qqxb40CRJ/0dJtgxdwyQ4BSaAncDOqtrc2jcDxwEkORc4FTh79/Aztu2KsfZy4JHxAe2m5y3AzzC6p+h3gHOSHPiKHoUkSS+TAUhU1b8DO5K8sXWdBHwryTrgQ8BpVfXkXja/C1iVZGWS/YAzgU1zK5PsC1wIfJTR9NpciJq7N0iSpIlzCkxzLgCubyHmIUZTVXcB+wO3JwG4s6p+P8mRwNVVdUpV7UryfuBLwBLgM1V1/9h+zweuraonk9wLJMl9wG1V9djkDk+SpBd4E/RLSLJllu8BSvA/wJSqIkPXIGn2zPrvvTlOgUmSpO4YgCRJUncMQJIkqTsGIEmS1B0DkCRJ6o4BSJIkdccAJEmSumMAkiRJ3TEASZKk7hiAJElSdwxAkiSpOwYgSZLUHQOQJEnqjgFIkiR1xwAkSZK6YwCSJEndMQBJkqTuGIAkSVJ3DECSJKk7BiBJktQdA5AkSeqOAUiSJHXHACRJkrpjAJIkSd2ZiQCUZEmSe5J8sbVXJtmc5MEkn02yX+vfv7W3t/VHDVm3JEkaxkwEIOBCYNtY+6+Aj1fVKuBR4LzWfx7waFUdDXy8jZMkSZ2Z+gCUZDnwTuDq1g5wInBzG3ItcHpbXt/atPUntfGSJKkjUx+AgL8GPgg839qvAx6rql2tvRNY1paXATsA2vrH23hJktSRqQ5ASU4Fvl9Vd493zzO0Xsa68f1uSLIlyRbg0J++UkmStJgsHbqAn9LbgNOSnAK8CjiI0RWhQ5IsbVd5lgOPtPE7gRXAziRLgYOBH+2+06raCGwEaCFIkiTNkKm+AlRVl1TV8qo6CjgT+HJVnQ18BfjtNuxc4Na2vKm1aeu/XFV7XAGSpElI8qokX0/yzST3J/nz1n9Skq1JvpHka0mO3sv2l7SnWh9I8o7Wd1jb5l+SnD429tYkR07myKTFb6oD0Iv4EHBRku2M7vG5pvVfA7yu9V8EXDxQfZIE8DRwYlUdC7wFWJfkeODTwNlV9RbgBuDPdt8wyWpGf/j9ErAO+FSSJcBZjB72OAH4kzb2XcDWqnpk9/1IvZr2KbD/VVVfBb7alh8C1s4z5r+BMyZamCTtRbsC/Z+tuW/7VPsc1PoP5oVp/HHrgRur6mng39ofdmuBZ4EDgP2B59t0/weAdy3UcUjTaGYCkCRNo3bV5m7gaODKqtqc5H3AbUmeAp4Ajp9n02XAnWPtuSdeb2ifdzO6Gv6HwHVV9eTCHYU0fWZ1CkySpkJVPdemupYDa5O8Gfgj4JSqWg78DfCxeTad96nWqnq8qt5ZVWuArcCpwC1Jrkpyc5ITFuhQpKliAJKkRaCqHmM0jX8ycGxVbW6rPgv8yjybzD3VOmf8idc5lwKXMbov6G7gvcDlr1zV0vQyAEnSQNoTW4e05QOA32T0Wp+Dk/xCG/Z2fvJVP3M2AWe2dxyuBFYBXx/b9yrgyKr6J+BARl8WW4y+MkTqnvcASdJwjgCubfcB7QPcVFVfTPJ7jKatnmf0PsP3AiQ5DVhTVZdW1f1JbgK+BewCzq+q58b2fRnw4bb8t8DnGb038dJJHJi02MWvwXlxSba0ufSZlOz5TdiaDlXz3gOiKeG5N91m+fyb9d97c5wCkyRJ3TEASZKk7hiAJElSdwxAkiSpOwYgSZLUHQOQJEnqjgFIkiR1xwAkSZK6YwCSJEndMQBJkqTuGIAkSVJ3DECSJKk7BiBJktQdA5AkSeqOAUiSJHXHACRJkrpjAJIkSd0xAEmSpO4YgCRJUncMQJIkqTsGIEmS1B0DkCRJ6s5UB6AkK5J8Jcm2JPcnubD1vzbJ7UkebP++pvUnyRVJtie5N8lxwx6BJEkawlQHIGAX8MdV9YvA8cD5SVYDFwN3VNUq4I7WBjgZWNU+G4BPT75kSZI0tKkOQFX13ara2pZ/DGwDlgHrgWvbsGuB09vyeuC6GrkTOCTJERMuW5IkDWyqA9C4JEcBbwU2Az9XVd+FUUgCDm/DlgE7xjbb2fokSVJHlg5dwCshyauBW4APVNUTSfY6dJ6+mmd/GxhNkQEc+ooUKUmSFo2pvwKUZF9G4ef6qvq71v29uamt9u/3W/9OYMXY5suBR3bfZ1VtrKo1VbUG+MGCFS9JkgYx1QEoo0s91wDbqupjY6s2Aee25XOBW8f6392eBjseeHxuqkySJPVj2qfA3gacA9yX5But70+BvwRuSnIe8B3gjLbuNuAUYDvwJPCeyZYrSZIWg1TtcQuMxiTZ0qbCZlKy5z1Qmg5V897TpinhuTfdZvn8m/Xfe3OmegpMkiTp/8MAJEmSumMAkiRJ3TEASZKk7hiAJElSdwxAkiSpOwYgSZLUHQOQJEnqjgFIkiR1xwAkSZK6YwCSJEndMQBJkqTuGIAkSVJ3DECSJKk7BiBJktQdA5AkSeqOAUiSJHXHACRJkrpjAJIkSd0xAEmSpO4YgCRJUncMQJIkqTsGIEmS1B0DkCRJ6o4BSJIkdccAJEmSumMAkiRJ3TEASZKk7hiAJElSd7oLQEnWJXkgyfYkFw9djyRJmryuAlCSJcCVwMnAauCsJKuHrUqSJE1aVwEIWAtsr6qHquoZ4EZg/cA1SZKkCestAC0Ddoy1d7Y+SZLUkaVDFzBhmaev9hiUbAA2tOYbk2xZ0KqGdffQBSywQ4EfDF3EQkiY5f+XPfDcm2Izfv69YegCJqG3ALQTWDHWXg48svugqtoIbJxUUVo4SbZU1Zqh65B647mnxa63KbC7gFVJVibZDzgT2DRwTZIkacK6ugJUVbuSvB/4ErAE+ExV3T9wWZIkacK6CkAAVXUbcNvQdWhinMqUhuG5p0UtVXvcAyxJkjTTersHSJIkyQAkSZL6YwCSJL1ikuw/dA3Sy2EA0szJyO8mubS1X59k7dB1SbMsydok9wEPtvaxST45cFnSXhmANIs+BZwAnNXaP2b0ElxJC+cK4FTghwBV9U3gNwatSHoR3T0Gry78clUdl+QegKp6tH3xpaSFs09VPZz8xBuHnhuqGOmlGIA0i55NsoT2nrckhwHPD1uSNPN2tKnmauffBcC3B65J2iunwDSLrgA+Bxye5DLga8Dlw5Ykzbw/AC4CXg98Dzi+9UmLkl+EqJmU5E3ASUCAO6pq28AlSZIWEQOQZk6Snwd2VtXTSX4dOAa4rqoeG7YyaXYluYo27TyuqjYMUI70kpwC0yy6BXguydHA1cBK4IZhS5Jm3j8Cd7TPPwOHA08PWpH0IrwCpJmTZGt7CuyDwFNV9ckk91TVW4euTepFkn2A26vqpKFrkebzPyGb3MgFhpB/AAAAAElFTkSuQmCC'></td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row0_col8" class="data row0 col8" ></td>
</tr>
<tr>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row1_col0" class="data row1 col0" >passenger_id</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row1_col1" class="data row1 col1" >1</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row1_col2" class="data row1 col2" >object</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row1_col3" class="data row1 col3" >Unique ID of the passenger</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row1_col4" class="data row1 col4" >0<br/> 0%</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row1_col5" class="data row1 col5" >891<br/> 100%</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row1_col6" class="data row1 col6" >other 100%</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row1_col7" class="data row1 col7" ><img src='data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAkAAAACQCAYAAADgO9QwAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADl0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uIDMuMC4zLCBodHRwOi8vbWF0cGxvdGxpYi5vcmcvnQurowAAGO1JREFUeJzt3Xu8HVV99/HPl4Sg3CQY1JY7ikoUEYxgX94AMaAVYxUUVIpURFvpBbAtoIAEqz5qpU8tXlDySA0SEKwECFIERC2iCcgtaGoIEGJAgYCoIJDwff5YKzpszgnJ3mcnZ87+vl+veWVmzZrfrD3Ze5/fXrNmRraJiIiIGCTrresGRESsJOl2SfvU+eMlfaXP+/uqpI/1Ie5HJc0c6bgRMXKSAEWMMZI2kHSGpDsk/UbSTyS9YRX1D5V0raQHJS2R9ClJ44eot6Ok3zf/sEvaRdJ8SfdKOqpRvr6kH0nautvXYfvjtg/vdvuIiFVJAhQx9owH7gReCzwDOAE4V9J2w9TfEPgHYBKwB/A64END1DsNmNtR9oladxfgI5KeU8uPBs63fWfXryIioo+SAEWMMbZ/Z/ujtm+3/bjti4DbgJcNU/8Ltr9v+1HbvwDOAl7ZrCPpIOAB4PKOzbcHrqjb/RzYRtI2wNuAU5+qrZIOqT1V90n6cMe6P5xGkvQ0STNrvQckzZX07LruMEk/rb1diyS9vxFjz9qrdXztpbpd0ruGacvNkvZvLK9ft3lpXX6FpKvr/m+QtGej7vaSrqptuIySTEbEKJYEKGKMq4nC84H5q7nJa5p1JW0KTAeOGaLuzcBUSVsB2wG3Av8O/JPtx56iXZOBLwCHAH8KPBPYapjqh1J6s7au9T4APFzX/Qp4E7ApcBhwqqTdGts+h5KQbFnjnC7pBUPs4z+BdzeW3wjcZft6SVsCFwMfAzan9HqdL2mLWvfrwLV1P6fU/UTEKJYEKGIMk7Q+pUfnTNs/W436hwFTgM80ik8BzhjmdNaHgL8GZgNHUXqOfgMsknRB7RU5cJjdHQBcZPt7th+hnKp7fJi6j1ESn+fZXmH7WtsPAti+2PatLq4C/ht4dcf2J9h+pK6/GHj7EPuYCbyxJnxQErOv1fl3A3Nsz6m9apcB82r9bYCXN/bxPeDCYV5HRIwSTxroGBFjg6T1KH/AHwWOXI36bwE+Cexj+95a9lJgH2DXobaxfQelpwRJGwJXA/sCnwPOoSQbN0u63Payjs3/lDJWaWWs30m6b5jmfY3S+zNL0maUZOXDth+rA7xPovRyrUcZ03RTY9v7bf+usXxH3Xfna1kq6X+At0n6L+ANwN/X1dsCBzZPkQHrA1fWWEPto+sB4BHRf0mAIsYgSQLOAJ4NvHE1TkftB3wZ+HPbzeRhT8qprcUlJBsD4yRNtr1bR5gTga/Y/qWknYGP2P61pCXA84Afd9S/C9ip0YYNKb08T1LbfzJwch3MPQdYUMcInQ/8JXBBTYi+Baix+URJGzUSlG0op+6GciZwOOW78Yd1bBOURO1rtt/XuYGkbYfZR26yFjGK5RRYxNj0BUpysb/th1dVUdLelNNkb7PdmaScDjwXeGmdvkjp1dm3I8ZkSrL0hVp0G7B3HX+0I7B4iF2fB7xJ0qskTaCMMxryO0nSXpJ2ljQOeJBySmwFMAHYALgHWF57g6YOEeJkSRMkvZoyXugbwxyObwG7UXp+/rNRPhPYX9K+ksbVQdl7Stqq9oLNa+zjVcD+Tw4dEaNJEqCIMab2SLyfkrDcLem3dXpXXb9NXd6mbnICZYDxnEbdSwBsP2T77pUT8Fvg97bv6djtacDf215Rl48D/o4ymPrjddsnsD0f+CBlAPFdwP3AkmFe1nMoCdODwE+Bq4CZtn9T93Nu3f6dlPFITXfXdUspid4HhhsPVZPF8ylXt32zUX4nMA04npJs3Qn8I3/8Dn0n5RYCyyin45rJU0SMQsqjMCJirKqXqs+0PdzVZUNtcyLwfNvvfsrKEdFaGQMUEVFJ2hx4L+UKsIgYw3IKLCICkPQ+yqmtS+ql7BExhiUB6oGk/SQtkLRQ0rG17CxJN0r6eKPeCZKmjYbYidveNudYrHlcyv2APrg6MW1/2fZGwLfG4rHI+yLHYqSOxZhhO1MXEzCOctfbHShXotwAvAQ4q67/PmVg6Z8AF46G2Inb3jbnWORY5FjkWKzruGNtyhig7u0OLLS9CEDSLODPgaer3IBuAuUy3emU+6OMhtiJ294251j0P24b25xj0f+4bWxzP4/FmJGrwJ6CpHsod3XtNJHy7KGV6zan3CTOwCbAfZRLdp81zPar0q/YidveNudY9D9uG9ucY9H/uG1sc69xt7W9xRDlY8u67oJa0wmYQXn44c3DrBflYYwLgRuB3RrrDqU8sfrnwKGrub95w5QfSLnr7crlQ4DPddS5kHKb/A9T7lPyvtXcZ19iJ25725xjkWORY5FjsbbiMszfvbE2tXEQ9FeB/Vax/g2UO8/uCBxBvTOtyuWtJ1FuVrY7cJKkiT20YwlPfNbPVpQbrVH3N41yd9iNgBfbfjtwiMrt/tdV7MRtb5tzLPoft41tzrHof9w2trmfx2LsWNcZWDcT5dlEw/UAfQk4uLG8gDLQ62DgS8PVW8W+husBGg8sotwxduUgsxfVdesDV1AeyrgL8PVa/gNgs9XYZ19iJ25725xjkWORY5FjsbbiMiA9QGNxEPSWNJ4wTcmEt1xFeVdsL5d0JHApZcT9DJdb+0O57PZM2w9JupHybMqbgDm2H1hXsRO3vW3OscixyLHIsVjXcceaVg6CVnka9EW2XzzEuouBT9j+QV2+HPgnYG9gA9sfq+UnAA/Z/tchYhxBOX0GMMn2dp11Tj755NU+cCeddJKeulY74/Yzdtvi9jP2WI7bz9hti9vP2G2L28/YbYvbz9hDxZU0z/aU1Y3RVm0cA/RUhjv3ucpzok22T7c9pb4B7u1XQyMiImLdGIsJ0GzgL1W8Avi17bsoXYFTJU1UGfw8tZZFRETEgGndGCBJZwN7ApMkLaFc2bU+gO0vAnOAN1Iug38IOKyuWybpFGBuDTXd9rK12/qIiIgYDVqXANk++CnWm2Ge/WN7BuU+QhERETHAxuIpsIiIiIhVSgIUERERAycJUERERAycJEARERExcJIARURExMBJAhQREREDJwlQREREDJwkQBERETFwkgBFRETEwEkCFBEREQMnCVBEREQMnCRAERERMXCSAEVERMTASQIUERERAycJUERERAycJEARERExcJIARURExMBpXQIkaT9JCyQtlHTsEOtPlXR9nf5X0gONdSsa62av3ZZHRETEaDF+XTdgTUgaB5wGvB5YAsyVNNv2LSvr2D6qUf9vgV0bIR62/dK11d6IiIgYndrWA7Q7sND2ItuPArOAaauofzBw9lppWURERLRG2xKgLYE7G8tLatmTSNoW2B64olH8NEnzJF0j6S39a2ZERESMZq06BQZoiDIPU/cg4DzbKxpl29heKmkH4ApJN9m+9Uk7kY4AjqiLk3pqcURERIw6besBWgJs3VjeClg6TN2D6Dj9ZXtp/XcR8F2eOD6oWe9021NsTwHu7bHNERERMcq0LQGaC+woaXtJEyhJzpOu5pL0AmAi8MNG2URJG9T5ScArgVs6t42IiIixr1WnwGwvl3QkcCkwDphhe76k6cA82yuToYOBWbabp8d2Ar4k6XFK4vfJ5tVjERERMThalQAB2J4DzOkoO7Fj+aNDbHc1sHNfGxcRERGt0LZTYBERERE9SwIUERERAycJUERERAycJEARERExcJIARURExMBJAhQREREDJwlQREREDJwkQBERETFwkgBFRETEwEkCFBEREQMnCVBEREQMnCRAERERMXCSAEVERMTASQIUERERAycJUERERAycJEARERExcJIARURExMBpZQIkaT9JCyQtlHTsEOvfI+keSdfX6fDGukMl/bxOh67dlkdERMRoMH5dN2BNSRoHnAa8HlgCzJU02/YtHVXPsX1kx7abAycBUwAD19Zt718LTY+IiIhRoo09QLsDC20vsv0oMAuYtprb7gtcZntZTXouA/brUzsjIiJilGpjArQlcGdjeUkt6/Q2STdKOk/S1mu4bURERIxhbUyANESZO5YvBLaz/RLgO8CZa7Atko6QNE/SPGBSL42NiIiI0aeNCdASYOvG8lbA0mYF2/fZfqQufhl42epuW7c/3fYU21OAe0eq4RERETE6tDEBmgvsKGl7SROAg4DZzQqS/qSx+Gbgp3X+UmCqpImSJgJTa1lEREQMkNZdBWZ7uaQjKYnLOGCG7fmSpgPzbM8G/k7Sm4HlwDLgPXXbZZJOoSRRANNtL1vrLyIiIiLWqdYlQAC25wBzOspObMwfBxw3zLYzgBl9bWBERESMam08BRYRERHRkyRAERERMXCSAEVERMTASQIUERERAycJUERERAycJEARERExcJIARURExMBJAhQREREDJwlQREREDJwkQBERETFwkgBFRETEwEkCFBEREQMnCVBEREQMnCRAERERMXCSAEVERMTASQIUERERAycJUERERAyc1iVAkvaTtEDSQknHDrH+aEm3SLpR0uWStm2sWyHp+jrNXrstj4iIiNFi/LpuwJqQNA44DXg9sASYK2m27Vsa1X4CTLH9kKS/Bj4FvKOue9j2S9dqoyMiImLUaVsP0O7AQtuLbD8KzAKmNSvYvtL2Q3XxGmCrtdzGiIiIGOXalgBtCdzZWF5Sy4bzXuCSxvLTJM2TdI2kt/SjgRERETH6teoUGKAhyjxkRendwBTgtY3ibWwvlbQDcIWkm2zfOsS2RwBH1MVJPbY5IiIiRpm29QAtAbZuLG8FLO2sJGkf4MPAm20/srLc9tL67yLgu8CuQ+3E9um2p9ieAtw7Yq2PiIiIUaFtCdBcYEdJ20uaABwEPOFqLkm7Al+iJD+/apRPlLRBnZ8EvBJoDp6OiIiIAdGqU2C2l0s6ErgUGAfMsD1f0nRgnu3ZwKeBjYFvSAJYbPvNwE7AlyQ9Tkn8Ptlx9VhEREQMiFYlQAC25wBzOspObMzvM8x2VwM797d1ERER0QZtOwUWERER0bMkQBERETFwkgBFRETEwEkCFBEREQMnCVBEREQMnCRAERERMXCSAEVERMTASQIUERERAycJUERERAycJEARERExcJIARURExMBJAhQREREDJwlQREREDJwkQBERETFwkgBFRETEwEkCFBEREQMnCVBEREQMnFYmQJL2k7RA0kJJxw6xfgNJ59T1P5K0XWPdcbV8gaR912a7IyIiYnRoXQIkaRxwGvAGYDJwsKTJHdXeC9xv+3nAqcD/qdtOBg4CXgTsB3y+xouIiIgB0roECNgdWGh7ke1HgVnAtI4604Az6/x5wOskqZbPsv2I7duAhTVeREREDJA2JkBbAnc2lpfUsiHr2F4O/Bp45mpuGxEREWOcbK/rNqwRSQcC+9o+vC4fAuxu+28bdebXOkvq8q2Unp7pwA9tz6zlZwBzbJ/fsY8jgCPq4guABavZvEnAvd2+tnUQt5+x2xa3n7HbFrefsdsWt5+x2xa3n7HbFrefsUdD3G1tb9GHNowq49d1A7qwBNi6sbwVsHSYOkskjQeeASxbzW2xfTpw+po2TNI821PWdLt1FbefsdsWt5+x2xa3n7HbFrefsdsWt5+x2xa3n7HbFrfN2ngKbC6wo6TtJU2gDGqe3VFnNnBonT8AuMKlq2s2cFC9Smx7YEfgx2up3RERETFKtK4HyPZySUcClwLjgBm250uaDsyzPRs4A/iapIWUnp+D6rbzJZ0L3AIsBz5oe8U6eSERERGxzrQuAQKwPQeY01F2YmP+98CBw2z7L8C/9Klpa3zabB3H7WfstsXtZ+y2xe1n7LbF7WfstsXtZ+y2xe1n7LbFba3WDYKOiIiI6FUbxwBFRERE9CQJUERERAycJEARERExcJIA9YGkjXvcfj1J69X5CZJ2k7T5yLTuSfvarR9xAyRtLmniCMecIukvJO0v6YUjFHMbSZvV+e0kHSDpxSMQ9yW9t27IuBPqo21WLu8l6RhJbxjh/WxcP3ubjWTcRvy/GcFY6w9RNmkE428q6WUj/X4eYj89vadV7CHprfVzskfzvdJj7C0k7Spp516/4zvijm/Mb1w/4z193/frPTvm2M40whOwuIdt3wL8EriL8uyyHwFXUG7iuH+P7dqtY3pZjbsrsFsPcV8IXAJcDDwX+CrwAOUeSzv1EHdryrPevg8cD6zfWPetPv3f3dTj9tvUNt8D/JzyvLlf1bLteoj7WmAe8B3gfuAi4H+A7wJb9xD3WOA24GfA4fXfM4D5wNE9HosV9fWfAkwewf+jG4CJdf4fgauBjwCXAZ/oIe7nG/OvAhYDV1Ien/PGHtt8dMd0DOWuvEf3cpyBvepn+B7gv5vvMeC6HuLOBCbV+X3rMfgOcAdw4Ej9Xw6x316+O6fW99slwFfq9O1aNrWHuJPra18IPFq/k2+r33PP6PH1vge4D/hfygO+FwGX1+N9cA9xl9c2vxfYrF//X22fWnkZ/Ggg6ejhVgG9/Do4CdgFeDrli/7lthdI2hY4H7iwh9jzgGuARxplzwQ+CxjYu8u4pwOfprzuK4B/Bg4D3gT8B/C6LuPOoLzmaygf5Ksk7W/7PmDbLmMi6a3DrQKe023c6hzg34B3ud5jStI4ym0ZZgGv6DLuv1G+xO+pN/H8rO1XSno9JWGZ2mXcQyhf8BsCtwM71H1sRPmi/2yXcQFurPEPBmZL+h1wNuWBxLf3EHec7fvr/DuAV9t+WNIngeuA47qM2/y/OQV4i+3rJO0AnEvHrTfW0Ml1+/mU9xmU+5ht0kNMgE9RHvszX9IBwGWSDrF9TWM/3djF9srHJpxEOca3116ly4FvdBtY0r8Ptwropefi/wL7dL636udlDrBTl3FnAIfW7+HdKfeP20PS+yifvQN6aPMxlMctbUL5vt/V9q2Snk1J6M/uMu5PKd8ZBwOfkvSDGusC2w/30N4xJafAuvdxYCLljducNqbH42r7bpen1S+2vaCW3dFrXODtwGPAp23vZXsv4O46323yA7CJ7Qttnw08ZnuWiwspx6hbW9j+ou3rXZ719nnge5KeS0nYunUO8GZg/47pTcDTeogL5VfzOW7cYNP2CtuzKMlmt8bZvqfOL6YmgLYvo7cH+q6oX4gPAA9Tfo1i+3c9xFzJtm+2/WHbzwPeBzwL+L6kq3uI+2DjFN29/PH/bDwj9522qe3rAGwvoiQrvXhRjbER5fN3MnC/7ZPrfLcm2J5f23kepQf5TEl/QW+fkfUkbVrnH6e856hJUa8/nA8Dbgau7ZjmUXpYujWe0hvW6RfAk04RroGnN76HfwzsXOe/TPnx0IsVtu+t3/e/tX1rjf3LHuM+Zvsi2++iPPLpLMr3/xJJX+8x9piRHqDuXUc5DXNt5wpJh/cSWNJ6th8H/qpRNg6Y0Etc2+dJ+jZwiqTDKL8+RuJGUM0/Dp09Br20eX1JT3O5sSW2Z0q6m3IX8I16iHsj8BnbN3eukLRPD3EBrpX0eeBMSjc2lFN5hwI/6SHuvPrw3sspp0a/CyBpQ3r743xd/ULcqMY+s75H9qbcMb0XT+iBqH88fizpGOA1PcT9AHCWpBsopxfnSboKeAnlh0m3XijpRkq7t5M00fb9dTxeL39Asb0YOEDSNEovzam9xGt4TNJzbN9d9zNf0usop0if20Pck4ErJZ1GOdX6DUkXUN4X3+6xzXOBm20/KQmW9NEe4s4A5kqaxRM/ewdRemq6daukEyifj7cC18Mfxl31+jd0saRPUH48/0zSvwLfBPahDIPo1h8+e/UHzrnAuZKeQUmSg9wIsWuSXgAsa/wqb657drcZvKSXU8ah/L6jfDvgVa5Psu+VpF0pycqL3eNTfyW9HzjL9m87yp8HHGn7H7qMexRlHMNVHeW7Ap+y/fou474auKP+UepcN8X2vG7i1u0nUE7XTaP0zIjyq3Q2cIbtR1ax+arirk/pQZlM6SqfYXuFpKcDz6o9hN3EHU85PWfgPGAPSrf5YuC0XnqCJL3Tdl9+bdYfBFOB5/PHX/6X2n6gh5idp1Xvsv1oPe3zGtvf7LrBT9zPRsBHgT1s95IIrkzY77F9Q0f5ZpRTNV3f9V7SjpRxYc1j/C3bl/bQZOoA39/bfqiXOMPEnkzp3X3CZ89218l8PZbH88fP3idt/6YmEzvV043dxt4U+CDl8/cfwH6UcUGLgVNsd5UESfqQ7c90265BkQRogNWrIzax/eC6bktERMTalDFAXVK5VP2vJF0s6QZJ10qaJWnPHuNuLGm6pPmSfi3pHknXSHrPCLR5vKT3S/p27eq/HjhH0gc0xGW03catx+OSQYvbEfuSEW7zyvfFzSP5vljF++3QXuI+Rex+tXlUxm1jm/v1Pu5zm/sVd4qkKyXNlLS1pMtq/LkqvdEjHfuBXmP3s81jSXqAuiTp/1EuCf0O5SqABymXa/8zZaT957qMewHwXzXu2yljM2ZRLvP9he3je2jz2ZTBrmfyx8GCW1HGp2xu+x2J233cPre5L++LPr/fWtXmHIsnxO3nZ6Rtx+LHlCvhNqNcdXdUHU/5OuBjtv+sm7j9jN3PNo8l/x/g3ufksU22JwAAAABJRU5ErkJggg=='></td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row1_col8" class="data row1 col8" ></td>
</tr>
<tr>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row2_col0" class="data row2 col0" >name</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row2_col1" class="data row2 col1" >2</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row2_col2" class="data row2 col2" >object</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row2_col3" class="data row2 col3" >Passenger's name</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row2_col4" class="data row2 col4" >0<br/> 0%</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row2_col5" class="data row2 col5" >891<br/> 100%</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row2_col6" class="data row2 col6" >other 100%</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row2_col7" class="data row2 col7" ><img src='data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAkAAAACQCAYAAADgO9QwAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADl0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uIDMuMC4zLCBodHRwOi8vbWF0cGxvdGxpYi5vcmcvnQurowAAGiFJREFUeJzt3Xm4XFWd7vHvSyAgKhgEJ0IgSLShQUEjbV8nWhmCinjFgQiIqKBeUdoZHBiCU0u3PlcaB5QgigoItgYJog2KAw4JDQJB0RCF5AYVBAUJAoH3/rHWgcqhToazq3LOPvV+nqee1N577d9etXOq6ldr2Fu2iYiIiBgkG4x1BSIihkj6vaQ96/P3SfpCn4/3RUkf6kPc4yWd2eu4EdE7SYAiJhhJG0s6TdINku6QdIWkfVdT/lBJl0u6XdIySR+XtGGXcjMk/b3zi13SUyUtknSLpLd3rN9I0s8lbTPa12H7I7bfMNr9IyJWJwlQxMSzIbAUeB6wOfBB4BxJ241QflPgX4EtgX8CXgC8q0u5U4AFw9Z9tJZ9KvABSY+r698BnGd76ahfRUREHyUBiphgbN9p+3jbv7d9v+1vA78Dnj5C+c/Y/pHte2z/P+ArwLM6y0g6EPgLcPGw3acDl9T9fgtMkzQNOAD45JrqKumQ2lL1Z0nvH7btgW4kSZtIOrOW+4ukBZIeW7cdJulXtbVriaQ3dsTYo7Zqva+2Uv1e0kEj1OUaSft1LG9U99m1Lj9T0mX1+L+UtEdH2emSLq11+B4lmYyIcSwJUMQEVxOFJwGL1nKX53aWlbQZMAd4Z5ey1wB7S5oKbAdcD3wKeI/te9dQr52AzwCHAE8AHg1MHaH4oZTWrG1quTcBd9VtfwJeDGwGHAZ8UtLTOvZ9HCUh2brGOVXSk7sc40vAwR3LLwRusn2lpK2BC4APAVtQWr3Ok7RVLftV4PJ6nBPrcSJiHEsCFDGBSdqI0qJzhu1fr0X5w4CZwL93rD4ROG2E7qx3AW8G5gFvp7Qc3QEskfSt2iryihEO93Lg27Z/aPtuSlfd/SOUvZeS+Oxg+z7bl9u+HcD2Bbavd3Ep8F3gOcP2/6Dtu+v2C4BXdjnGmcALa8IHJTH7cn1+MDDf9vzaqvY9YGEtPw14RscxfgicP8LriIhx4iEDHSNiYpC0AeUL/B7gyLUo/1LgY8Cetm+p63YF9gR267aP7RsoLSVI2hS4DNgHOBk4m5JsXCPpYtu3Dtv9CZSxSkOx7pT05xGq92VK689Zkh5FSVbeb/veOsD7OEor1waUMU1Xd+x7m+07O5ZvqMce/lqWS/oJcICk/wL2BY6qm7cFXtHZRQZsBHy/xup2jFEPAI+I/ksCFDEBSRJwGvBY4IVr0R01C/g88CLbncnDHpSurRtLSB4BTJK0k+2nDQtzLPAF23+UtAvwAdt/lbQM2AH4xbDyNwE7dtRhU0orz0PU+p8AnFAHc88HrqtjhM4DXgN8qyZE3wTUsfsUSQ/vSFCmUbruujkDeAPls/GndWwTlETty7YPH76DpG1HOEYushYxjqULLGJi+gwludjP9l2rKyjp+ZRusgNsD09STgWeCOxaH5+ltOrsMyzGTpRk6TN11e+A59fxRzOAG7sc+lzgxZKeLWkyZZxR188kSf8iaRdJk4DbKV1i9wGTgY2Bm4GVtTVo7y4hTpA0WdJzKOOFvj7C6fgm8DRKy8+XOtafCewnaR9Jk+qg7D0kTa2tYAs7jvFsYL+Hho6I8SQJUMQEU1sk3khJWP4g6W/1cVDdPq0uT6u7fJAywHh+R9kLAWyvsP2HoQfwN+Dvtm8edthTgKNs31eXjwHeRhlM/ZG67ypsLwLeQhlAfBNwG7BshJf1OErCdDvwK+BS4Ezbd9TjnFP3fzVlPFKnP9RtyymJ3ptGGg9Vk8XzKLPbvtGxfimwP/A+SrK1FHg3D36GvppyCYFbKd1xnclTRIxDyq0wImKiqlPVz7Q90uyybvscCzzJ9sFrLBwRrZUxQBERlaQtgNdTZoBFxASWLrCICEDS4ZSurQvrVPaImMCSADUgaZak6yQtlnR0XfcVSVdJ+khHuQ9K2n88xE7c9tY552Ld41KuB/SWtYlp+/O2Hw58cyKei/xd5Fz06lxMGLbzGMUDmES56u32lJkovwSeAnylbv8RZWDp44Hzx0PsxG1vnXMuci5yLnIuxjruRHtkDNDo7Q4str0EQNJZwIuAh6lcgG4yZZruHMr1UcZD7MRtb51zLvoft411zrnof9w21rmf52LCyCywNZB0M+WqrsNNodx7aGjbFpSLxBl4JPBnypTdx4yw/+r0K3bitrfOORf9j9vGOudc9D9uG+vcNO62trfqsn5iGesmqHV9AHMpNz+8ZoTtotyMcTFwFfC0jm2HUu5Y/Vvg0LU83sIR1r+CctXboeVDgJOHlTmfcpn891OuU3L4Wh6zL7ETt711zrnIuci5yLlYX3EZ4Xtvoj3aOAj6i8Cs1Wzfl3Ll2RnAEdQr06pMbz2OcrGy3YHjJE1pUI9lrHqvn6mUC61Rj7c/5eqwDwd2tv1K4BCVy/2PVezEbW+dcy76H7eNdc656H/cNta5n+di4hjrDGw0D8q9iUZqAfocMLtj+TrKQK/ZwOdGKreaY43UArQhsIRyxdihQWb/WLdtBFxCuSnjU4Gv1vU/Bh61FsfsS+zEbW+dcy5yLnIuci7WV1wGpAVoIg6C3pqOO0xTMuGtV7N+VGyvlHQkcBFlxP1cl0v7Q5l2e4btFZKuotyb8mpgvu2/jFXsxG1vnXMuci5yLnIuxjruRNPKQdAqd4P+tu2du2y7APio7R/X5YuB9wDPBza2/aG6/oPACtv/0SXGEZTuM4AtbW83vMwJJ5yw1ifuuOOO05pLtTNuP2O3LW4/Y0/kuP2M3ba4/Yzdtrj9jN22uP2M3S2upIW2Z65tjLZq4xigNRmp73O1faKdbJ9qe2b9A7ilXxWNiIiIsTERE6B5wGtUPBP4q+2bKE2Be0uaojL4ee+6LiIiIgZM68YASfoasAewpaRllJldGwHY/iwwH3ghZRr8CuCwuu1WSScCC2qoObZvXb+1j4iIiPGgdQmQ7dlr2G5GuPeP7bmU6whFRETEAJuIXWARERERq5UEKCIiIgZOEqCIiIgYOEmAIiIiYuAkAYqIiIiBkwQoIiIiBk4SoIiIiBg4SYAiIiJi4CQBioiIiIGTBCgiIiIGThKgiIiIGDhJgCIiImLgJAGKiIiIgZMEKCIiIgZOEqCIiIgYOEmAIiIiYuAkAYqIiIiB07oESNIsSddJWizp6C7bPynpyvr4jaS/dGy7r2PbvPVb84iIiBgvNhzrCqwLSZOAU4C9gGXAAknzbF87VMb22zvKvxXYrSPEXbZ3XV/1jYiIiPGpbS1AuwOLbS+xfQ9wFrD/asrPBr62XmoWERERrdG2BGhrYGnH8rK67iEkbQtMBy7pWL2JpIWSfibppf2rZkRERIxnreoCA9RlnUcoeyBwru37OtZNs71c0vbAJZKutn39Qw4iHQEcURe3bFTjiIiIGHfa1gK0DNimY3kqsHyEsgcyrPvL9vL67xLgB6w6Pqiz3Km2Z9qeCdzSsM4RERExzrQtAVoAzJA0XdJkSpLzkNlckp4MTAF+2rFuiqSN6/MtgWcB1w7fNyIiIia+VnWB2V4p6UjgImASMNf2IklzgIW2h5Kh2cBZtju7x3YEPifpfkri97HO2WMRERExOFqVAAHYng/MH7bu2GHLx3fZ7zJgl75WLiIiIlqhbV1gEREREY0lAYqIiIiBkwQoIiIiBk4SoIiIiBg4SYAiIiJi4CQBioiIiIGTBCgiIiIGThKgiIiIGDhJgCIiImLgJAGKiIiIgZMEKCIiIgZOEqCIiIgYOEmAIiIiYuAkAYqIiIiBkwQoIiIiBk4SoIiIiBg4SYAiIiJi4LQyAZI0S9J1khZLOrrL9tdKulnSlfXxho5th0r6bX0cun5rHhEREePBhmNdgXUlaRJwCrAXsAxYIGme7WuHFT3b9pHD9t0COA6YCRi4vO5723qoekRERIwTbWwB2h1YbHuJ7XuAs4D913LffYDv2b61Jj3fA2b1qZ4RERExTrUxAdoaWNqxvKyuG+4ASVdJOlfSNuu4b0RERExgbUyA1GWdhy2fD2xn+ynAfwNnrMO+SDpC0kJJC4Etm1Q2IiIixp82JkDLgG06lqcCyzsL2P6z7bvr4ueBp6/tvnX/U23PtD0TuKVXFY+IiIjxoY0J0AJghqTpkiYDBwLzOgtIenzH4kuAX9XnFwF7S5oiaQqwd10XERERA6R1s8Bsr5R0JCVxmQTMtb1I0hxgoe15wNskvQRYCdwKvLbue6ukEylJFMAc27eu9xcRERERY6p1CRCA7fnA/GHrju14fgxwzAj7zgXm9rWCERERMa61sQssIiIiopEkQBERETFwkgBFRETEwEkCFBEREQMnCVBEREQMnCRAERERMXCSAEVERMTASQIUERERAycJUERERAycJEARERExcJIARURExMBJAhQREREDJwlQREREDJwkQBERETFwkgBFRETEwEkCFBEREQMnCVBEREQMnNYlQJJmSbpO0mJJR3fZ/g5J10q6StLFkrbt2HafpCvrY976rXlERESMFxuOdQXWhaRJwCnAXsAyYIGkebav7Sh2BTDT9gpJbwY+DryqbrvL9q7rtdIREREx7rStBWh3YLHtJbbvAc4C9u8sYPv7tlfUxZ8BU9dzHSMiImKca1sCtDWwtGN5WV03ktcDF3YsbyJpoaSfSXppPyoYERER41+rusAAdVnnrgWlg4GZwPM6Vk+zvVzS9sAlkq62fX2XfY8AjqiLWzasc0RERIwzbWsBWgZs07E8FVg+vJCkPYH3Ay+xfffQetvL679LgB8Au3U7iO1Tbc+0PRO4pWe1j4iIiHGhbQnQAmCGpOmSJgMHAqvM5pK0G/A5SvLzp471UyRtXJ9vCTwL6Bw8HREREQOiVV1gtldKOhK4CJgEzLW9SNIcYKHtecBJwCOAr0sCuNH2S4Adgc9Jup+S+H1s2OyxiIiIGBCtSoAAbM8H5g9bd2zH8z1H2O8yYJf+1i4iIiLaoG1dYBERERGNJQGKiIiIgZMEKCIiIgZOEqCIiIgYOEmAIiIiYuAkAYqIiIiBkwQoIiIiBk4SoIiIiBg4SYAiIiJi4CQBioiIiIGTBCgiIiIGThKgiIiIGDhJgCIiImLgJAGKiIiIgZMEKCIiIgZOEqCIiIgYOEmAIiIiYuC0MgGSNEvSdZIWSzq6y/aNJZ1dt/9c0nYd246p66+TtM/6rHdERESMD61LgCRNAk4B9gV2AmZL2mlYsdcDt9neAfgk8G91352AA4F/BGYBn67xIiIiYoC0LgECdgcW215i+x7gLGD/YWX2B86oz88FXiBJdf1Ztu+2/TtgcY0XERERA6SNCdDWwNKO5WV1XdcytlcCfwUevZb7RkRExAQn22Ndh3Ui6RXAPrbfUJcPAXa3/daOMotqmWV1+XpKS88c4Ke2z6zrTwPm2z5v2DGOAI6oi08GrlvL6m0J3DLa1zYGcfsZu21x+xm7bXH7GbttcfsZu21x+xm7bXH7GXs8xN3W9lZ9qMO4suFYV2AUlgHbdCxPBZaPUGaZpA2BzYFb13JfbJ8KnLquFZO00PbMdd1vrOL2M3bb4vYzdtvi9jN22+L2M3bb4vYzdtvi9jN22+K2WRu7wBYAMyRNlzSZMqh53rAy84BD6/OXA5e4NHXNAw6ss8SmAzOAX6ynekdERMQ40boWINsrJR0JXARMAubaXiRpDrDQ9jzgNODLkhZTWn4OrPsuknQOcC2wEniL7fvG5IVERETEmGldAgRgez4wf9i6Yzue/x14xQj7fhj4cJ+qts7dZmMct5+x2xa3n7HbFrefsdsWt5+x2xa3n7HbFrefsdsWt7VaNwg6IiIioqk2jgGKiIiIaCQJUDQmaZKkA8a6HhEREWsrXWDjkKSNgQOA7egYp2V7To/ibw1sOyz2DxvG/JHt5zStW5e4jwU+AjzB9r71dib/bPu0BjHfsZrNdwPXA9+1ff9oj9EPko4CTgfuAL4A7AYcbfu7DeNuAFxle+fmtWwvSVOB7Wz/uC6/A3hE3fxV24t7cIydKbfw2WRone0v9SDuFOAJwF3A78fb32439TZEj2XVz6EbG8bs62dnL0naYnXbbd+6vuoyqFo5CHq8kPRM4GRgR2AyZVbanbY3axj6W5SrV19O+ULuGUn/BryKMhNuaAacgUYJEHCRpH8FzgbuHFpp+/aGcb9I+dJ/f13+TT3GqBMg4JGr2TYFeAHwOuCV6xJU0vmUc9nNUGJ1iu2lI5RZk9fZ/r/1Jr5bAYdRzk2jBMj2/ZJ+KWla0y+g4STdwYPnZDKwEQ3eI2s4x9h+yWjiVicBX+lYfiNl4OimwAnAQQ1iI+k4YA9KAjSfcj/DHwOjSoAkbQ68BZhNObc3UxKrx0r6GfBp299vUN9NgBcDz+HB5Ooa4ALbi0Ybt8Z+K3Ac8EdgKFkz8JQmcenvZ+ezgON58MejANvefpQhL6e8ZgHTgNvq80cBNwLTG9b3ZZT7YD6mxh2qb9PvpwkjCVAz/0mZYv91YCbwGmCHHsSdantWD+J081LgybZ7+uFA+bIAeCcPvqlNeWM3saXtcyQdAw9cBqHRpQtsn7CmMpKuGkXof1/Ntg0pN+E9B/jnUcSGck4BXgicbvuX9R53vfB4YJGkX7BqAtskocD2KsmmpJfS7P57Q+f4ZcDjgDPr8mzg9w3iQnlffLtjeYXt/4DSwtkwNpRrkj0VuML2YbV18wsN4p1LSZ6eY/svnRskPR04RNL2o2ktlXQ8sB/wA+DnwJ8oydWTgI/V5OidtkfzPgE4inK+/zzK/UfSz8/O04C3UxKXxpdPsT0dQNJngXl1djOS9gX2bBof+Diwn+1f9SDWhJQEqCHbiyVNqtcTOl3SZT0Ie5mkXWxf3YNYwy2h/ArvaQJke5s1lxqVOyU9mvqrv7a6/bVPx3qA7XX+JWr70jUUuVhSk1+4l0v6LuWX4TGSHsmDv56bWmNS2Au2vynp6Ab7Xwog6UTbz+3YdL6kpq2YmwxbfkHH80c3jA1wV21tWylpM0pSMdrWA2zvtZptl1O+qEdrge3jR9j2CUmPodmPm6X0533cz8/Ov9q+sA9xn2H7TUMLti+UdGIP4v4xyc/qJQFqZkW9GvWVkj4O3AQ8vAdxnw28VtLvKInKUNNl0+ZhgBWU+l5MRxJk+21Ngkp6GOVX3ba23yxpB2BGDz4w3kG5gvcTJf2E0vXz8oYxx8zQPexG6fXArsAS2ytqYnhYj+p1qaRtKf9n/y1pU0qXbiO1GX7IBpSW0l4MPNyqtm4sqceZTvnbaOIOSU+y/Rt4cAyGpH8A/tYwNsBCSY8CPk9JTv5GD65EL+k8YC5wYa/G/ti+YA3b/0RJ4EZrCfADSRew6ufQJxrEhP5+dn5f0knAN1i1zv/TMO4tkj5Aac00cDDQi5axhZLOBr7JqvX9Rg9iTwgZBN1A/cL4I6X//e2Ue459uulgyRr3IWzf0CRujX1ot/W2z2gY92vA1cCrbe9cv0B/Ynu3JnFr7A0pN6UVcJ3te5vGbKPa3XUQsL3tOZKmAY+z3Ysv0cMpNwDewvYTJc0APmv7BWvYdU1xT+9YXEnppvp8/QJtEncWZXzOkrpqO+CNti9qGPNTlAulDn2pPR14H3BUL3/9S9oO2KxBF1JnrD0pifAzKd3xX7T966Zxa+ytgPfy0IHbz28Y97hu69eme3oNcfv52dltPJV7cC62oIyHei4Pjsec03QQ9LD33hDbfl2TuBNJEqBxRNJmtm8faXbAeJ4VMHSjPUlXDCU9kq60vWvDuG8BvjI0xqHOdplt+9M9qHPPZ5h1OcYGwCN6MBgcSZ+hdHk93/aO9Vx81/YzehD7SsrYnJ93/P9dbXuXprH7pc74+Ye6+OtejGurs7TeQxmvBWXQ70m2r2kau8Z/Cg+dodSTX+R1UPRsyoSBpZSWpjOb/GCoXa5nA+8C3kS5x+LNtt/bvMb9IenZlJbM02sC9wjbvxvrenVTZ8J9zPa7x7ougyhdYA10mRUAQINZAV+lzLronB3wQFgajBcYUn/Zf5SH/qJrGvueOjByaKzOdOCehjEBDrd9ytCC7dtqa0XjBIj+zDBD0lcpXxb3Uf4vN5f0CdsnNYkL/JPtp0m6Ah44F5Mbxhxyt+17hsZU11a3Uf86kvQe2x+XdHK3OD3oct2U0j26re3DJc2QNHwQ8zqric5rmsQYiaS5lFlOi1h15lPjBKh2hx4MHAJcQZnN9mxKwrJHg9CPtn2apKPq+KtLJa1prNva1HcrHkw0e92yNJPSYnw6ZbzjmcCzmsStsTfnwZYagEspLTWjHstk+746YL3nVC7rcDLltZsy4/Ao28v6cbw2SgLUTK9nBby4/tto+uManE55E38S+BdK03kvZhLNAb4DTJV0BvA8ypiVpjaQJNemyvqLqVdf+j2fYVbtVFvyDqJMd34v5W+kaQJ0b339Q+diK3o3CPpSSe8DHiZpL+D/AOc3iDc0+HJh45p1dzrlnA7NqFtG6f5plAD12TNt79TroJK+QWkJ+zJl1s9NddPZkpqe/6HWo5skvQhYDkxtGBNKgnY25QffAy1LPYj7vynXx/ofANvL62SBXphLaREcujzGIZS/w5eNuMfauULSPMrfb+cMzKaJ8emUH9VD98U8uK4bcfD8oEkC1Ey/ZgUMdfXMYNVfR01nuQA8zPbFNam4ATheZYpv1z75tWX7O5IuB/4XJaF6d9NxHtVFwDkqU0VN+bD8Tg/iQv9mmG0kaSPKJQf+0/a9knrR1/wp4L+Ax0j6MGUw+Ad6EBfgaErCejXlkgbzaTBF2/ZQ8rTC9tc7t0nqeqPidfRE26+SNLse7y6pZ5cE6JefStrJ9rW9Cli7WK+03fVL2PbMhof4UG35eCelNWEzyo++pvrSsgTcY9tD7zdJvZiUMuSJtjuveH9C7TpuagvKoOfO1q9etAxuZbtzHNAXVa7VFtX/B2uq3T01pmbkAAAAAElFTkSuQmCC'></td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row2_col8" class="data row2 col8" ></td>
</tr>
<tr>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row3_col0" class="data row3 col0" >pclass</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row3_col1" class="data row3 col1" >3</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row3_col2" class="data row3 col2" >int64</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row3_col3" class="data row3 col3" >Passenger's class (1st, 2nd, or 3rd)</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row3_col4" class="data row3 col4" >0<br/> 0%</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row3_col5" class="data row3 col5" >3<br/> 0%</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row3_col6" class="data row3 col6" >3 55%<br/> 1 24%<br/> 2 21%</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row3_col7" class="data row3 col7" ><img src='data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAkAAAACQCAYAAADgO9QwAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADl0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uIDMuMC4zLCBodHRwOi8vbWF0cGxvdGxpYi5vcmcvnQurowAAElRJREFUeJzt3Xu87fWcx/HXx+nQXVHRROGRRz9yOXEkTOTazdZ4VCZmEqrzQKVMDBVFaRSDLi45KZVLSZIO5TAUMqOLJqM6PxyXODQqkehen/nju2pS55y9z9lrrd/a6/t6Ph7r8dj70dq/32f9Tr/ffu/vNTITSZKkmjyk6wIkSZKGzQAkSZKqYwCSJEnVMQBJkqTqGIAkSVJ1DECSJKk6BiBJklQdA5AkSaqOAUiSJFXHACRJkqpjAJIkSdUxAEmSpOoYgCRJUnUMQJIkqToGIEmSVB0DkCRJqs4qXRcw6iLieuCaruuQZoBNMnP9rotYFu9lacpG+l7uFwPQ5K7JzLldFyGNuoi4rOsaJuG9LE3BDLiX+8IuMEmSVB0DkCRJqo4BSJIkVccxQNKwtDFvhd7f5PwBVSJJ1bMFSJIkVccAJEmSqmMAkiRJ1TEASZKk6jgIWpLUiYmJiWOAOV3XUZFNgesXLFiwRdeFjAIDkCSpK3NWe9jdL9hog9u6rqMKv1iyOvdkrNl1HaPCACRJ6sxGG9zG/rv9susyqvD2457EbbfP6rqMkeEYIEmSVB0DkCRJqo4BSJIkVccAJEmSqmMAkiRJ1TEASZKk6hiAJElSdQxAkiSpOgYgSZJUHQOQJEmqjgFIkiRVxwAkSZKqYwCSJEnVMQBJkqTqGIAkSVJ1DECSJKk6BiBJklSdqgJQRDw2Ii6IiEURcVVE7N91TZIkafhW6bqAIbsLODAzL4+ItYAfRsQ3M/PqrguTJEnDU1ULUGZem5mX976+GVgEbNRtVZJGxcTExDETExPHdF2HNAh33hkAq3Vdx6iorQXoPhHxOGAL4OJuK5E0QuZ0XYA0KPdkAMzquo5RUWUAiog1gS8BB2Tmn5fy3+cB83rfrjfM2iRJ0uBV1QUGEBGzKeHnc5l59tLek5nzM3NuZs4FbhhqgZIkaeCqCkAREcBJwKLM/HDX9UiSpG5UFYCA5wG7Ay+KiCt6rx26LkqSJA1XVWOAMvMiILquQ5Ikdau2FiBJkiQDkCRJqo8BSJIkVccAJEmSqmMAkiRJ1TEASZKk6hiAJElSdQxAkiSpOgYgSZJUHQOQJEmqjgFIkiRVxwAkSZKqYwCSJEnVMQBJkqTqGIAkSVJ1Vum6AEkaIZsCa05MTFzYdSGVmHP9Hx/adQ2qlAFI0tiKiHnAvN6363VZi6TRYgCSNLYycz4wHyAiLpvCjywGWLBgwTYDLEs9ExMTF66/7h0v6LoO1ckxQJIkqToGIEmSVB0DkCRJqo4BSJIkVccAJEmSqmMAkiRJ1XEa/LhpY97kb+ppcv4AK5EkaWTZAiRJkqpjAJIkSdUxAEmSpOpUF4Ai4uSIuC4iruy6FmkZ1gXm0saOtLF+18VI0jiqLgABpwDbdV2EtBSrA68HjgL2Br4KLKGNw2lj1U4rk6QxU10AyszvAjd2XYf0AOsAhwDPAr4OHAlsDZwFvBv4Gm2s3l15kjRenAavmWdFpvrDTJjuvwbwVmBN4IPALwFo8iLgItpYSGm5PJs2dqTJuzuqU5LGRnUtQFMREfMi4rKIuAxYr+t6NPZeS/n/7HjuDT/31+RpwBuBbSmtRJKkaTIALUVmzs/MuZk5F7ih63o01rYG5gBnA4uX+a7SivUZ4DDaeN5wSpOk8WUAkrqzNrALcDXw7Sm8fx9gCXACbcweZGGSNO6qC0ARcTrwX8BmEbEkIvbsuiZVa2fKOLzPAznpu5u8GdgfeArwloFWJkljrrpB0Jn56q5rkIBNgK2A84DrV+DnvtL7mUNp49M06YxGSVoJ1bUASSPi5cBfKVPep67JBN4JrAUc2P+yqndF7yWNnYdEAjiLtKe6FiBpBGwMPA04B7h9hX+6yR/TxpnA/rRxDE2uSAuSlmPBggUHdF2DNCizZyd3386tXdcxKmwBkoZvR+AW4MJpHOM9wGrAO/pQjyRVxwAkDddjKNPevwXT+EusyRb4LLAPbWzYn9IkqR4GIGm4dqAEn6lMe5/M4ZRu7IP6cCxJqooBSBqevwOeSQk/t0z7aE3+nLJFxjzaePS0jydJFTEAScOzA2XQ87f6eMyjgdnAv/TxmJI09gxA0jC00QBzgQso09/7o8nFwBnAm2jjEX07riSNOQOQNByHAHcC3xzAsd9P2Ul+vwEcW5LGkgFIGrQ2ngi8hjLt/S99P36TV1JWiN6fNtbq+/ElaQwZgKTBOxi4A/jGAM9xJLAu8MYBnkOSxoYBSBqkNp4A7A6cANw8sPM0eSmle+1A2lhtYOeRpDFhAJIG6yDgLuCDQzjXkcCjgDcM4VySNKMZgKRBaWMT4HXAiTT5uyGc8bvA94F/pY2HDuF8kjRjuRnqTNfGKsBzgOdTtlnYHLgR+CnwC+Ce7oqr3qGU6/+BoZytyaSNIyg7zO8NfGwo55WkGcgANFOVv/DfDLyVsrt4AjcAqwL3zgS6EfgP4DuUbhgNSxubU1p/jqXJ3wzxzN+gzDY7lDZOpcn+zzqTpDFgF9hM1MbfAz8GPgL8CvhH4JE0uQHwNuAAYD7wB+BVlJaITTuptV5HUQY9HznUszaZlHFHG1DCsSRpKWwBmknaCOBdwHsowWd7mvz6Ut55K/DD3mtz4NXAgcBZ9HcbhuFo48nArsALgc2AtSnTyv8XWET5nNd3Vt8DtfF84OXAQTT5h6Gfv8kf0MaXgbfTxgk0OTrXRpJGhC1AM0UbsykbXx4OnA7MWUb4eaCrgPcBP6K0Bu0NPGxAVfZXG8+mjYWUz3AYsDpwPvADSvBZA3glcATwJspmo90qIfVo4LfAcR1Wcgjl+hzcYQ2SNLJsAZoJyuq+XwS2pXRnva/X1TFVt1HWodmWEhg2oNtfzsvXxiOBDwOvBX5P+SV+Mk3+vvff593v3esCW1Nahw6l7LX1ZUoLURdeBWwF7EWT09/xfWU1uYg2Pg28mTY+QZM/7awWSRpBtgCNujYeRfml/hLKL9UjVjD83N9C4KPAo4F39LZoGC1tvIzS4vMayh5Xm9Lk++8LPw/2R+BcSovHd4AX9b7eeAjV/q021gGOAS4HTh36+R/sEEp36Md7LVOSpB5bgEZZCSgLKYvb7USTX+vDUa8EPkTZOPM/aWNHmrykD8ednjZmUcY2HQJcDWxHk1eswBFuoXQN/jfweuCdlGC0sL+FLtfRlNa1HWmy+1l3Tf6eNg4CPg78M/CZjiuSHuS3163KsWc8vusyqnDHHbZ53J8BaFS1sSVwb+B5YZ9Dyq8ov6zfAFxAG7vS5Hl9PP6KaWND4PPANsDJwH7T6D5qgfcC/0Tp7tuUNr5Ikzf2o9RlnzUmgHnAv9Pk5QM914qZT7kWx9PGhUOeki9N5opbb5/F4t+s0XUdtdiUUZow0jED0ChqY0fgTMosp+1o8mcDOMt1lAUUzwPOpY29afLTAzjP8rWxDXAGZWbX62iyH11HtwAnAj+jjMm5nDZeNbCWrjY2ogS3Kyiz9EZHk3fTxh6UQfCn0cZLR6J1SgIWLFhwQNc1qF62h42SNoI29gW+Qpnl9NwBhZ+ijKvZhjI1/mTaeNfQxoq08RDaeEfv3DcBW/Yp/Nzfhfz/KswX0ca+ff98baxO6WpbFXgNTd7e1+P3Q5M/B/ah/Fu/v9tiJGk0GIBGRVnZ+ZPA8ZSurxcuZ+Bv/zR5MzBBGR9yBDB/4LuJt/EI4BzKYoFnAXNp8soBne1XwDMoKyQfD5xOG2v35cjl3+wMYA6wG00u6stxB6GEy48Bb6ONPbsuR5K6ZgAaBW1sTNmyYm/g34BX9oLJcDR5B7AHZdXivYCLaeNJAzlXGztRZnltB7yFEhwG+1nL+J9XUFZI3hW4ujdmZ+WVkPhFSnjct08D1AftrZR9wk6kjd26LkaSumQA6lLp8tqTMjPrGZQulENocvgbmDaZNPkuYAfKNPkf0sabe7Ozpq+NDWnjdErLz3XAVjR5/DSm9K+YJu+hyaOA53Lv1Pk2zqSNx67wsdp4PGXX9QlgH5r8RF9rHZQm7wR2Br4HfJ429uu4IknqjAGoK21sQflr/FOUrRyeSpOnd1sU0OT5wNOBiyhdJpfQxstWeuxMGxvQxocoO9PvTFms8FmdzZRq8mLgmZTByq8AfkYbH6WNzSb92TbW6k0rvxJ4AjBBkx8fZLl9V2bXbU8Zt3QcbZzWty5BSZpBqpsFFhHbAccCs4BPZeZRQzt5CRHPpKx18w/AnyjdQB/rpNVnWZq8lja2BXajTJdfSGkR+iTwZZq8Ybk/38YqlJaW3SkLGq4KfBY4vDcgt1uly+9I2vgs8G7K9PV9aONSyqy4S4FrKIsIrg00lIUodwYeTmnF2p8mf91B9dPX5C20sTPls78beDFtHAx8zhlikmpRVQCKiFmUVo2XAkuASyPi3My8emAnLV1ITwF2omxK2lBmPR0GHEuTNw3s3NNRuqZOp42zgdcB+1LWlDmBNq6ghISfAzcCdwNrUlZffiplK4h1gL8CXwCOpsmfDPsjTKrJa4C9aOMQyhioXSiBYGktozcBXwWOG4mFI6erybuB99DG+ZTB4acA76WNE4EvAT8ZWvekJHWgqgAEbAkszsxfAETEGZRgsvIBqI2GsrjUKpRWpbWAjXqvzSktPmsASdmq4RjgCzT5p5U+5zCVad2fpI35wBaU67U1ZX2ddR/w7juAn1Jmdi0EFg51MPfKKrPtPgB8oLfv2tOAxwAPpawptBi4ujeGZrw0eTFtbEXpDjyAsnHu+4AbaeMSysravwa+M9Kz3CRpBdUWgDYC7r8S7hLg2dM85h6UbRce6EbKQnwnAZcAF9Dk76Z5ru6U1oDLe6+ijYdTuoRmUVp7bhiprryVUQLb97suY6jKv9k5wDm9QeHbU/5Y2JLSWjqL0lVrAJI0NiIrauWOiF2BbTNzr973uwNbZuZ+D3jfPMq4EIDNgNHrvlm29YDlj9GZ+Wr4jDDzPucmmbl+10UsS0RcTxnbNZmZdt3vZd3DNc51j/S93C+1tQAtAe4/7fkxwINaZTJzPmW8y4wTEZdl5tyu6xikGj4j1PM5h2WqD/SZet2te7ise+arbRr8pcATI+LxEfFQyiynczuuSZIkDVlVLUCZeVdE7EsZoDsLODkzr+q4LEmSNGRVBSCAzDyPstbLuJqRXXcrqIbPCPV8zlEzU6+7dQ+Xdc9wVQ2CliRJgvrGAEmSJBmAxkVEnBwR10XElV3XMigR8diIuCAiFkXEVRGxf9c1DUJErBoRl0TEj3qf871d1zRuJrtfojguIhZHxP9ExDOGXePSTKHubSLipoi4ovc6dNg1Ls1U7t1RvOZTrHvkrvlUniER8bCI+ELvel8cEY8bfqXdMgCNj1OA7bouYsDuAg7MzCdRttvYJyKe3HFNg3A78KLMfDowB9guIrbquKZxcwrLv1+2B57Ye80DPjGEmqbiFCa/z7+XmXN6r8OHUNNUTOXeHcVrPtVnzqhd86k8Q/YE/piZmwIfoez7WBUD0JjIzO9SVp8eW5l5bWbZRT4zb6asTLxRt1X1XxZ/6X07u/dysF4fTeF+2Qk4rfdv8QNgnYjYcDjVLdtMvc+neO+O3DWfqc+cKT5DdgJO7X19FvDiiIghlTgSDECakXrNtVsAF3dbyWBExKyIuAK4DvhmZo7l5xxhS9s2Z+R/8fU8p9f1cX5EbN51MQ+0nHt3pK/5JM+ckbvmU3iG3He9M/MuyobPjxxuld0yAGnGiYg1KTuWH5CZf+66nkHIzLszcw5ltfItI+IpXddUmaX9JTwTWuEup2xj8HTgeMoebyNjknt3ZK/5JHWP5DWfwjNkZK/3sBiANKNExGzKg+hzmXl21/UMWmb+CbiQ8R/fNWqmtG3OqMnMP9/b9dFb82x2RKzXcVnAlO7dkbzmk9U9ytcclvsMue96R8QqlI2tZ1z36nQYgDRj9PqnTwIWZeaHu65nUCJi/YhYp/f1asBLgLbbqqpzLvDa3sykrYCbMvParouaTEQ8+t5xHBGxJeUZ/4duq5ryvTty13wqdY/iNZ/iM+RcYI/e17sA387KFgasbiXocRURpwPbAOtFxBLgsMw8qduq+u55wO7Aj3t92wAH9/7qGicbAqdGxCzKw/TMzPxqxzWNlaXdL5SBomTmCZTV4ncAFgO3AK/vptK/NYW6dwHeFBF3AbcCu43IL7Wl3rvAxjDS13wqdY/iNV/qMyQiDgcuy8xzKcHuMxGxmNLys1t35XbDlaAlSVJ17AKTJEnVMQBJkqTq/B/JlXVSgUkxqwAAAABJRU5ErkJggg=='></td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row3_col8" class="data row3 col8" >2/10 0.24 27%</td>
</tr>
<tr>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row4_col0" class="data row4 col0" >age</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row4_col1" class="data row4 col1" >4</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row4_col2" class="data row4 col2" >float64</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row4_col3" class="data row4 col3" >Passenger's age</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row4_col4" class="data row4 col4" >177<br/> 20%</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row4_col5" class="data row4 col5" >89<br/> 10%</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row4_col6" class="data row4 col6" >[0.42, 20.125, 28.0, 38.0, 80.0]<br/> mean: 29.70 std: 14.53<br/> cv: 0.49 skew: 0.39*<br/> log skew: -2.30</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row4_col7" class="data row4 col7" ><img src='data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAkAAAACQCAYAAADgO9QwAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADl0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uIDMuMC4zLCBodHRwOi8vbWF0cGxvdGxpYi5vcmcvnQurowAAGWJJREFUeJzt3XuYHFWZx/Hva64YJJEAigkkgQTkooTdLHIJC2tAERjiriKxYUUE4yU8iqBcVuFRFFduElxBibCIaBnYeMsgENCggo9gAkQgRGAMYCYEQSDhlosD7/5xKjDpdM/0zHT3qer6fZ6nn+6uPnX6nZo+Pe+cOnWOuTsiIiIiRfKG2AGIiIiINJsSIBERESkcJUAiIiJSOEqAREREpHCUAImIiEjhKAESERGRwlECJCIiIoWjBEhEREQKRwmQiIiIFI4SIBERESkcJUAiIiJSOEqAREREpHCUAImIiEjhKAESERGRwlECJCIiIoWjBEhEREQKZ3DsALLOzJ4GHo8dh0gOjHP3bWMHUY3askjNMt2W60UJUO8ed/cpsYMQyTozWxw7hl6oLYvUIAdtuS50CkxEREQKRwmQiIiIFI4SIBERESkcjQGS2iQ2s+prJZ/TxEhEREQGTD1AIiIiUjhKgERERKRwlACJiIhI4SgBEhERkcLRIGgRkRxra2ubDUyuU3UT0/uOOtVXbkl7e/spDapbpE+UAImI5NvkLQa/ctCYkesGXFHnmuEAjB25bsyAKyuzcs1w1nYNqne1Iv2mBEhEJOfGjFzHZw98dMD1XHr7BIC61FWp7o5nRtS9XpH+0hggERERKRwlQCIiIlI4uUyAzOwwM3vIzDrM7MwKrw8zs+vS1+8ys/Hp9n3MbEl6+5OZ/XuzY29BW5PY3iS2bexAREREapW7MUBmNgi4DDgU6AQWmdl8d3+wW7ETgefcfaKZzQDOB44BHgCmuHuXmW0P/MnM2t29q8k/Rt4ZsC/QBowG/huAxBYBlwM/oOSvRotORESkF3nsAdoH6HD35e6+AZgLTC8rMx24Jn08D5hmZubuL3dLdoYD3pSIW8sbgJOAjwIvAD8GPgCcRTimVwN/ILGJ1SoQERGJLY8J0BhgRbfnnem2imXShGcNoacCM3uXmS0F7gc+qd6fPjsBmAL8DPgG8BtK/lNK/g1gL+AjhLlEFpHYIfHCFBERqS53p8AIp1/KlffkVC3j7ncBe5jZbsA1ZnaTu28ygYaZzQQ2rn6+zQDjbSX7E3rgfgHc/NrWzVeKvwiYBdxEYkdS8gVNi1BERKQGeUyAOoEduj0fCzxRpUynmQ0GRgLPdi/g7svM7CVgT2Bx2WtzgDkAZrbJawU2CvgQ8AhwUy9lnwEuBk4F2knsYmDziUVKPqfOMYqIiNQkj6fAFgGTzGyCmQ0FZgDzy8rMB45PH38QWOjunu4zGMDMxgG7Ao81J+zcawOGEMZW1TJ26iXgEmA18GlCAiUiIpIJuUuA0jE7JwMLgGXA9e6+1MzONbOj0mJXAaPNrIPQC7HxUvmphCu/lhDGsHza3f/e3J8ghxLbEdgPuB14ug97vki4Ym8o8Aly+HkTEZHWlMdTYLj7jcCNZdvO6fZ4HXB0hf2uBa5teICt5/T0/pZ+7LsK+CHhyrHDgRvqFZSIiEh/6T9y6VliWwEfA+6ibBxVHywC7gSOBHasU2QiIiL9pgRIenMMsAXwuwHWcx1h3qDj0OdOREQiy+UpMGmAzS9l3+gMwmmsgS4P/TIhCfo4cBBw2wDrExER6Tf9Jy49eQuwE/D7OtW3GPgz4VTYFnWqU0REpM+UAElPphAuef9jHeucB2wJHFbHOkVERPpECZD0ZDKwnLCUSL2sIAyonkZiO/RWWEREpBGUAEk1WxOu2FrSgLp/Tliu5NwG1C0iItIrJUBSzeT0vhEJ0LPAQuB4EntnA+oXERHpka4Ck2r2Ilz99VSD6r8JOBC4msSu2OxVrRMmEbS1tc0GaG9vPyV2LJJv+ixlnxIgqWQoMAn4dQPf42VCL9ARwPaEZEsktsm9FxGpiT5LGadTYFLJJGAQYa21RloIrCcskSEiItI0SoCkkt2ALuCRBr/Pi8BvgX8Btmvwe4mIiLxGCZBUsjvQAfyjCe91KyHZ0rxAIiLSNEqApNxWwBjgwSa93/PA7cC+wOgmvaeIiBScEiApt0t6/+cmvueC9P7QJr6niIgUmBIgKbcLsI4wY3OzrCbMDn0AYZkMERGRhlICJOUmAX8BXm3y+y4AhgDvbvL7iohIASkBku62BN4GPBzhvZ8kzDr9b8CwCO8vIiIFogRIupuY3jf68vdqFgBvJMwQLSIi0jBKgKS7XQiXvj8e6f0fBR4CDiWxoZFiEBGRAlACJN1NBB4jzMsTy83AKODYiDGIiEiLy2UCZGaHmdlDZtZhZmdWeH2YmV2Xvn6XmY1Ptx9qZneb2f3pvQbcvm4oMJYwAWJMDxKuQDuDxHL5+RQRkezL3R8YMxsEXAa8jzBj8YfNbPeyYicCz7n7ROAS4Px0+9+BNnd/B3A8cG1zos6FcYT1v/4SOxBCL9CuwPTYgYiISGvKXQIE7AN0uPtyd98AzGXzP5TTgWvSx/OAaWZm7n6vuz+Rbl8KDDczXXEU7JzePxo1iuAeQiJ2JolZ7GBERKT15DEBGsOmk/R1ptsqlnH3LmANmy+z8AHgXndf36A482Yn4G+EBUpjexW4kJDsHhw3FBERaUV5TIAq9Qh4X8qY2R6E02KfqPgGZjPNbLGZLQa26W+guRF6WXYmG6e/NrqGkJCdETsQERFpPXlMgDqBHbo9Hws8Ua2MmQ0GRgLPps/HAj8DPuLuFf/gu/scd5/i7lMI44Za3UTCJIjZSYBKvg6YDbyXxPaOHY6IiLSWwbED6IdFwCQzmwCsBGYApbIy8wmDnP8AfBBY6O5uZqOAXwJnufvvmxhz1u2f3i+PGsXmvgOcRegFmhE5FhGRPmtra5tGmOT1EMI8Z3OBY9rb25+sUn4v4HfAX4Edgant7e33l5XZvrd6qtTdr/1aVe56gNIxPScTPlDLgOvdfamZnWtmR6XFrgJGm1kHcCqw8VL5kwm9HWeb2ZL0tl2Tf4Qs2g9YC6yKHcgmSr6GkAQdTWI791ZcRCSDridcYTsPOBuYmt5X80NgK2DP9D6pUKaWeirp734tKXcJEIC73+juu7j7zu5+XrrtHHefnz5e5+5Hu/tEd9/H3Zen27/m7iPcfXK321Mxf5aM2J/Q+1M+lioLZhNmpz4rdiAiIn00Ctg6fTwaOIHwd/eEtra2t5YXTnt/9izbvGdbW9s7upXZvrd6Kunvfq0sj6fApJ4SG0locDfEDqWikj9JYlcAs0jsAkoeY6FWKY6JwJZtbW2/iR1IH0x++qXsrxyTxjg5Z8d2ICYDbyrbNjy9fwOhF2ZW2es/rFJXAmxMgs7m9Qt9qtVTSX/3a1m57AGSunoXoVFkZwD05r4OrAO+EjsQyZfCXdEpWVPtb+ww4LgK28t7fyptPzbdv6d6Kunvfi1LPUCyH+HUVxYmQKys5H8jsdnAF0nsfEq+JHZIkg/uPgeYA5AmQb3pAGhvbz+4gWHVVVtb22+2HbHhoNhx9GbbERtYs27Ikjwd24FIe7r2B4ZUeHk9lXt7HqByEvRAt8c/Aj5GSGKq1VNJf/drWeoBkqmExrUudiC9uAhYDXwtdiAiIjV6sOz5xu/ZV4GvVihfrVem+5XOX+X18ZrV6qmkv/u1LCVARZbYYEIP0O2xQ+lVyVcTJq88gsSmxg5HRKQGq0nnoAOeAa4mJB9XV7oMvb29/U9s2tsD8ED3y+Db29tX9VZPJf3dr5UpASq2ycAI8pAABd8iTHr5LRIbFDsYEZEafAh4hTAn3VeBO+i59+U44HlCIvQ8m89zR431VNLf/VqSxgAV28aelDuAw2MGUpOSv0xinwOuAz4FfDtyRCIiPWpvb/81m/6t7XG8VtoLNLKXMqt6q6ee+7UqJUDFNhV4jJJ3kmRs0fXEZvbw6q3AeSQ2j5IXvhtXRET6TqfAiiosgHog+Tn91d3JhPk0LowdiIiI5JMSoOKaCGxHOP2VL2EyxAuA40hsWuxwREQkf5QAFdeB6X0ee4AgTI74MHA1iY2KHYyIiOSLEqDimkq4LPPPsQPpl5KvJVwt8Tbgu+kpPRERkZooASquA4E7KHkWF0CtTckXAecAxwCfjhyNiIjkiK4Cy6qeroIq+ZwB1v1WwhigKwZUTzZ8gzCZ42wSe4CS/zZ2QCIikn3qASqmjfP/5HX8z+tK/irwn8AjwHwSe2fkiEREJAeUABXTQcDLwL2xA6mLsEzGYcALwM0kNj5qPCIiknlKgIrpvcBvKPmG2IHUTcn/Svi5tgAWpKf5REREKlICVDSJTQAmAQtih1J3JV8KtAFjgNtJbFzkiEREJKM0CLp43pPe3xI1ioHoeZkMCGuEfQa4h8QuAZ567ZWBDiAXEZGWoB6g4nkP8FfgodiBNNBy4CJgCPAFYGzccEREJGuUABVJYkOBacAtuZ7/pzadhCSoC/g84bJ/ERERIKcJkJkdZmYPmVmHmZ1Z4fVhZnZd+vpdZjY+3T7azG4zsxfN7NvNjjsD3g2MBH4RO5AmeZKwYOoa4BTgHXHDERGRrMjdGCAzGwRcBhxK+C9/kZnNd/cHuxU7EXjO3Sea2QzgfMJsweuAs4E901vRfJFwDHasYRxNq3iWkAR9Bvg0if2Rkl8bOSbJriWxA5CWoc9SxuUuAQL2ATrcfTmAmc0FpgPdE6DpwJfTx/OAb5uZuftLwB1mVrzTIYkNBiYD9xFOCxXJi8DFhOUyfkBiW1Ly70SOSTKovb39lNgxSGvQZyn78pgAjQFWdHveCbyrWhl37zKzNcBo4O9NiTCb/hXYErgndiCRrAf+B/gEcDmJ7QfcsUkJXSEmIlIYeRwDVGnV7/IBvbWUqf4GZjPNbLGZLQa26UtwGfYxYC2wNHYgEXUR1j97gLCS/H5xwxERkVjymAB1Ajt0ez4WeKJaGTMbTBj4+2ytb+Duc9x9irtPoRV6jRLbBjgauBNondmf+6cL+A6wDDgemBI3HBERiSGPCdAiYJKZTTCzocAMYH5ZmfmEP24AHwQWurf8Zd89OQEYCmil9GBjEtRB6BnT1WEiIgWTuwTI3buAkwlLOSwDrnf3pWZ2rpkdlRa7ChhtZh3AqcBrl8qb2WPAN4GPmlmnme3e1B+g2RIbBswirPy+KnI0WbKBMGN0J2Fc0KS44YiISDPlcRA07n4jcGPZtnO6PV5HOOVTad/xDQ0ue2YB44CZwPi4oWTOOuBbhIkSTyaxuZT87sgxiYhIE+SuB0j6ILGtgS8RZn7O79pfjfUiMBt4CbiZxHaLHI+IiDSBEqB8eRPwVhIb1WvJMO9Pku7zhQbHlXergUuAV4BbSWx81GhERKThcnkKrIAOIKzhNSZ9/hUS6wB+Tpjo8Y+brO2V2HDCbNnvBT5Bye9rbri59DRhodjfEpKgAyn5k5FjEhGRBlEClG3DCVcp7UVYwX0eYV2rh4GDgc8Sxq+sILGfEVZ43wYoAbsCX9fkfn1Q8vtI7H3Ar4BbSOwgSv5c7LBERKT+lABl11DC1W47AdcBC197JSQ1F6SnwtoIl/p/Mt3HCbM9v1fjfvqh5HeS2PuBXwK3kdgRlHxl7LBERKS+lABlUWJG6PmZCFwJLK5YruSrgWuBa0lsCGG5j7WUfE2TIm1NJf8ViR1F6HG7k8QOp+T3xw5LRETqR4Ogs+lkYG/gJ1RLfsqV/B+U/EklP3VS8gXAgYQ2cgeJHRE5IhERqSMlQFmT2B7ARYRV22+NHE2xlXwJsC/wKHADiV1OYm+MHJWIiNSBToFlSWJvAL4LvABcEzma4klsZpVX5hDGYp0GTCOxkyj57c0LTERE6k0JULacAEwljP8Z0q8aqv8Rl/7rouSfJ7EbgauB35HYXOB0Sr4icmwiItIPSoCyIrFtgQsIa3Z9H/h4D2WV5MRQ8oXpTNFnAKcD00nsQuBCSv5i3OBERKQvNAYoOy4EtgI+ucmkhpINic1ME8/jgJXAucBS4BzgYRL7GIkNihmiiIjUTglQFiR2MHA8oSfhwcjRSG2eAb4HnE+YpPIq4G4SmxY1KhERqYlOgcWW2DDgCmA58LXI0UjfLU9v9wH/AfyKxO4Dricsr4Fm45ZGW7lmOJfePmHA9XSuGQ5Ql7rKrUzrFskKJUDxnQXsQpi5+eXYwUi/LQaWENZsOxz4MnALcFPEmKQYlqztGkTHMyPqUddEgI5nRnTUo7IKljSoXpE+UwIUU2JvJyRAiZataAldwALgTkJv0OHAviT2JPATje2SRmhvbz8ldgwieaQxQLG8PufPy8CpkaOR+lpDuFz+QsLv9/8IK8zvFjUqERF5jRKgeL4AHAScRsn/FjsYaYgO4DxgFvDPwH0kdhGJvTluWCIiogQohsQOIPxhvJ7QUyCt61VKfjlhnNf3Cb19K0hsNomNjxiXiEihKQFqtsR2AX5BWF9qpsaFFETJn6bkHwf2IixyOwv4C4ndQmInkNiouAGKiBSLBkE3U0h+bgEceJ9Wbi+gkt8PHE9iXwQ+CcwEDgW+R2J/AR4ElgGPU/Ir4gUqItLacpkAmdlhwKXAIOBKd/9G2evDgB8Qxl08Axzj7o+lr50FnAi8AnzG3Rc0JegwQd5cQvJzGCVv1GWmkjXVly75K/AlYBzhs7ob8P709jKJHQ7cAfweuJuSr29CtCIihZC7BMjMBgGXEf5r7gQWmdl8901mUD4ReM7dJ5rZDMJsvceY2e7ADGAP4G3Ar8xsF3d/pWEBJzaO8EfuJOAhoI2SP9Kw95M8ejy9AWwJvB3YnZAQHZVuX09iiwjJ0L2EZTgepuQbmhyriEhLyF0CBOwDdLj7cgAzmwtMJ5w62Gg6YSI6gHnAt83M0u1z3X098KiZdaT1/aEukSVmwCjCgNd9gCOAQ4BXgW8CZ2uyQ+nFi4RJFRdT8jkkth1wQLfbqcCQtOwrJLaKsDbZSsI/BH8nXIa/Or3vfnseWAuspeSvNu0nEhHJoDwmQGOAFd2edwLvqlbG3bvMbA0wOt1+Z9m+YwYUTWKnAJ8iJD6jgKHdXl1OmAvmckq+osLeItVteurs4fR2LfAWwud2e+DN6W0c4fNX23oDia0nzFG0Nr2tIyTqXuV2MSX/8UB/JBGRrMhjAmQVtpVfSVWtTC37YmYzCYNTAXY1s8W9xPRCequU5BwKHMqxld66qm0I/8lnheLpWex4XkpvK9PnjYjnNI6103opM67O71lv42poy7F/l/2luJsvr7HXEnfW23Jd5DEB6gR26PZ8LPBElTKdZjYYGAk8W+O+uPscINoClma22N2nxHr/coqnZ4onH9x9297K5PXYKe7my2vseY27EfI4D9AiYJKZTTCzoYRBzfPLyswHjk8ffxBY6O6ebp9hZsPMbAIwCfhjk+IWERGRjMhdD1A6pudkwqKTg4D/dfelZnYusNjd5wNXAdemg5yfJSRJpOWuJwyY7gJmNfQKMBEREcmk3CVAAO5+I3Bj2bZzuj1eBxxdZd/zCMtQZFm0029VKJ6eKZ7Wkddjp7ibL6+x5zXuujPXSgwiIiJSMHkcAyQiIiIyIEqAMsTMDjOzh8ysw8zOjPD+O5jZbWa2zMyWmtln0+1bm9mtZvZIev/mJsc1yMzuNbMb0ucTzOyuNJ7r0sHwzYxnlJnNM7M/p8dqv5jHyMw+l/6+HjCzH5vZ8NjHKG9it72+yGo7rVXW2nMtstbm+0LfD9UpAcqIbkt8vI+wDMKH06U7mqkLOM3ddwP2BWalMZwJ/NrdJwG/Tp8302cJC4RudD5wSRrPc4SlT5rpUuBmd387YXX3ZUQ6RmY2BvgMMMXd9yRcGLBx+ZeYxyg3MtL2+iKr7bRWWWvPtchMm+8LfT/0TAlQdry2xIe7byAsnDq9mQG4+yp3vyd9/AKhkY9J47gmLXYNYbHOpjCzsYQlRa5MnxvwbsISJzHi2Qr4V8KVhrj7BndfTcRjRLiYYYt0zqs3AquIeIxyKHrb64ssttNaZa091yKjbb4v9P1QhRKg7Ki0xMfAlukYADMbD+wN3AW8xd1XQfjyBbZrYiizgdMJyzRAWNJktbt3pc+bfZx2Ap4Grk678a80sxFEOkbuvhK4iLCy/CrCml93E/cY5U2m2l5fZKid1ipr7bkWmWrzfaHvh54pAcqOmpbpaAYz2xL4CXCKuz8fI4Y0jiOBp9z97u6bKxRt5nEaDPwT8B1335uwBEW0ru903MF0YALwNmAE4VROOV3uWV3sz1S/ZKWd1iqj7bkWmWrzfaHvh54pAcqOmpbpaDQzG0L4Uv2Ru/803fw3M9s+fX174KkmhXMAcJSZPUY4LfFuwn+Qo9LuXGj+ceoEOt39rvT5PMKXY6xjdAjwqLs/7e7/AH4K7E/cY5Q3mWh7fZGxdlqrLLbnWmStzfeFvh96oAQoO2pZ4qOh0vPxVwHL3P2b3V7qvrTI8cAvmhGPu5/l7mPdfTzheCx092OB2whLnDQ1njSmJ4EVZrZrumkaYWbxKMeI0LW9r5m9Mf39bYwn2jHKoehtry+y1k5rlcX2XIsMtvm+0PdDDzQRYoaY2eGE/4g2LvHR1BmrzWwqcDtwP6+fo/8vwviC64EdCQ3qaHd/tsmxHQx83t2PNLOdCP9Bbg3cCxzn7uubGMtkwiDOocBy4ATCPxNRjpGZfQU4hnB10L3ASYRz+tGOUd7Ebnt9keV2WqsstedaZK3N94W+H6pTAiQiIiKFo1NgIiIiUjhKgERERKRw/h9JGjaqwz/bJgAAAABJRU5ErkJggg=='></td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row4_col8" class="data row4 col8" >7/10 0.02 3%</td>
</tr>
<tr>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row5_col0" class="data row5 col0" >birth</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row5_col1" class="data row5 col1" >5</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row5_col2" class="data row5 col2" >datetime64[ns]</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row5_col3" class="data row5 col3" >Created from minusing the titanic happened date from Age</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row5_col4" class="data row5 col4" >177<br/> 20%</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row5_col5" class="data row5 col5" >72<br/> 8%</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row5_col6" class="data row5 col6" >1832-05-03<br/> 1874-04-23<br/> 1884-04-20<br/> 1892-04-18<br/> 1912-04-14</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row5_col7" class="data row5 col7" ><img src='data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAkAAAACQCAYAAADgO9QwAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADl0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uIDMuMC4zLCBodHRwOi8vbWF0cGxvdGxpYi5vcmcvnQurowAAIABJREFUeJztnXm8XfO5/9+PkBhijiEkZkEISW6IVEWINKqtiqlc1BDl3tKrSosaltUaOxhuB62fGOq6vS1aVVRC5AitpiLmpBIRQ4wx1RhEnt8fz3dlr7Ozh7WHc/Y+ez/v1+u81l7Td32/e1jns57pK6qK4ziO4zhOO7FCozvgOI7jOI7T3bgAchzHcRyn7XAB5DiO4zhO2+ECyHEcx3GctsMFkOM4juM4bYcLIMdxHMdx2g4XQI7jOI7jtB0ugBzHcRzHaTtcADmO4ziO03a4AHIcx3Ecp+1wAeQ4juM4TtvhAshxHMdxnLbDBZDjOI7jOG2HCyDHcRzHcdoOF0CO4ziO47QdLoAcx3Ecx2k7Vmx0B5odEVkEPN/ofjiO4zhON7Gpqq7X6E50NS6AyvO8qo5odCccx3EcpzsQkZmN7kN34C4wx3Ecx3HaDrcAOY7j9BAkllHAGKBDI32wwd1xnB6NW4Acx3F6AEH8TAXOB6aGdcdxqqQlBZCIrCwi/xCRx0TkKRGJw/bNRWSGiMwTkd+JSO9G99VxHCcjY4A+2H27d1h3HKdKWlIAAR8De6nqTsBQYB8R2RW4BLhMVbcG3gYmNrCPjuM4ldCRer0kb91xnAppSQGkxvthdaXwp8BewM1h+/XA/g3onuM4TjXMBD4Jry/3GCDHqY2WFEAAItJLRB4FXgfuBuYD76jqknDIQmDjRvXPcRynQoYDK4fX2siOOE4r0LICSFU/U9WhwABgF2C7QocVOldEjheRmaEWQr8u7KbjOE5WRoflW8DmjeyI47QCLSuAElT1HcxXviuwlogkqf8DgJeLnHOVqo4IBRDf6JaOOo7jlGY08DQwC9iiwX1xnB5PSwogEVlPRNYKr1cB9gbmANOAg8JhRwF/akwPHcdxsiOx9AJ2B6YDC3ALkOPUTEsKIKA/ME1EHgceAu5W1duB04HviMgzwLrApAb20XEcJys7AGuSE0D9JJa+je2S4/RsWrIStKo+DgwrsP1ZLB7IcRynJ5HE/0wHPhdebw480ZjuOE7Pp1UtQI7jOK3EaOB5jfQFzAIE7gZznJpwAeQ4jtPESCyCCaDpYZMLIMepAy3pAnMcx6mFaiYd7cKJSgcB65MTQIuAD8kogHwCVccpjFuAHMdxUgTBcC/wQzJOOlrNORWQjv9BI1UyZoJ1cb8cp0fjAshxHKczY7BJR3th0+iMyXDOWKxKcyXnZGU08BowL7Utayr8GHJj8QlUHSeFCyDHcZzOdKReZ5109M3U608znpOV0cD0YPlJeBbYPMQHlSLdD6lzvxynR+MCyHEcpzPPYmIB4KqMcTMDU6/3r1esjcSyKbAJufifhAVAX6yeWSkeD8u3sPt9lwVOSyyjJJYz3c3m9BRcADmO43QmqSH2KbBNxnPGA+93QV86xf+kyJoJNhgTcycAM4ArJJa6zm8osWwksdwM/A2PNXJ6EC6AHMdxOjM8LG8E9pBYVil1sMSyXjjnSmyC5ZF17Mto4B3gybztWQXQjmH5GHAcVk368np0TGJZT2L5CTAfmBA2d0UMlON0CS6AHMdxOjMMc4P9Hgts3r3M8ePC8iZszsF6C6D7NdKleduzCqAhwEfAsxrpk8CFwOESyxer6Uxwc8USyzXYe3QK9j4dgok/pf4xUI7TJbgAchzH6cxwbMb1+4BPMPdWKcZjMTazMDfTrhmCk8sisWyI1QDKd3+hkb6HBV5nEUBPaaSfhfWLgNnAryWW1SvszyhsQulzgWOwse6gkR6lkd4CzAQWAmO93pDTE3AB5DiOE5BY1gK2AGZppB8C9wNfKHG8hP13B5ExAwtM3qIO3UksT8sJoECWVPghpOYL00g/xlxhAzBrUCWMwVLpAT4Dpmqkc1L7HwJWB/5eYbuO0xBcADmO4+QYGpaPhOVkYAeJZeMix+8IbBiOAxNAUB832Gjgg1Rf8ikpgCSWDYD1yJswNVhnfgacKLFcWUHAckfSBGYZ68jbPxdYC6hrkLXjdBUugBzHcXIkGWBpAQTFrUDJ9ilh+SQ2TUW9BNDfNNJPi+xfAGwqsRS7jw8Jy0Izxv8pLP+D7Flbz2AZZZMp7OaaG5aDMrTlOA3HBZDjOE6O4cDLGulrYf0J4BWKxwGNB57USF8C0EiXAA9TowCSWNbBBEwx9xeYAOoNbFRkfykBNBKz5ED2CtG7hOXFRWJ8XAA5PQoXQI7jODmSAGhg2bxbU4BxEkuv9IESy2pYnM4UOjMDGCax9KmhH7th1pZyAgiKu8GGAItSYi5NB/BxeK1ky9oaCSzFBF4hnscywFwAOT0CF0CO4zQMiWVvieWsZiicJ7GsCmzL8jE3U4B1yNUHStgDs55Mzts+I2zfqYbuHIoFGpfKJssigApZf5I4oLHAc8DcjFlbIzFrV8GCj8H6NR8XQE4PwQWQ4zgNIYieKTRP9eAdsXvirLztd2NWknw32HhgMZYplqamQOjwPhyGFRX8S4n35fnQr+UEULBWbU9uKozlCKLnRmAbiaVvmT6tgLnAZpQ6DnODZa2e7TgNxQWQ4ziNYhxm4RCao3pwfgA0ABrpIkwUFRJA92mkH+VtX4jFDVUbB3QYOctP0fclpLS/TGEL0BbAKhSxAKWYjgmtcuJzayzDq5wAehrYKt9d6DjNiAsgx3EaxdOp10tpfPXg4VhBwxcK7JsMjJJY1oRlk5Ruw/LxP0nc0AyqF0BJUPMSyldVLpYKXyoAOs2DmKttdJnjkrFksQD1ofPksI7TlLgAchynUbwVlp8Bs5ugevAwrACiFtg3BbOU7BnWk/T3/PifhBmYJaTcbO2dCPOO7R2udy7lqyqXEkAKPFXqeqGi9CyyCaD3sak+SuGZYE6PwQWQ4ziNIrESTAKGSiwN+6cpsayEiYZiRQcfxARA4gYbD7yETStRiMRSskuR/cU4AJuw9BKN9KIMonABMEBi6Z23fQgwP1SzLsd0YGSZrLWRwEOpKTWK4QLI6TG4AHIcp1EMxKwUF2JWoGMb2JfBWOZWfgA0ABrpJ8C9wHiJZUXMSjO5iLUIbF6samaGn4iJmo6Mxy/A4oU2ydteNAOsANMxt9XOhXYGq9ROlHd/AbwGvIcLIKcH0JICSEQGisg0EZkjIk+JyMlh+zoicreIzAvLtRvdV8dpYwYCr2mkzwN3AkcFS0wjSFLci1mAwNxdmwP/jllpirm/EtfSk1QggCSWLTEX2zUFZn8vxnKp8EGwbEV2AfRAWBZzgw0HViSDAAqCcC4ugJweQEsKICx48FRV3Q7YFThRRAYDZwBTVXVrYGpYdxynMQwEXgyvr8bm1Nq3QX0Zhrm45pU4Jgl4vgCz7kwt0+YMYJcKZoY/BgsGvy7j8VC4FtBg7N6eSQBppG+FY4sJoKwB0AkugJweQUsKIFV9RVVnhdfvYYF7GwNfBa4Ph10P7N+YHjqOQ2cBdCfwKuYCqisSyyiJ5cwydYaGA4+VsrxopM9gcT8DgDka6ZtlLj0DK6C4VYY+9gKOBu7SSBeWOz7FS1imWFoAZc0ASzMd2C249/IZCbygkb6Ssa25wGY1VsJ2nC6nJQVQGhHZDHu6mwFsoGo/4rBcv3E9c5z2JVhFlgmgUEX4emBfiaV/Ha8zCrPUFC22GIr8DaVI/E9eWxuE1UEZCjcmFpNdM3R1PPaQNinDscsIQckvsLwAWoxNXpqV6UBf7H3IZyTZrT9gAkjIIPwcp5G0tAASkb7ALcC3VfXdCs47XkRmishMoF+XddBx2pe1sH+4L6a2XYOlmh9Vx+uMwQJ8e1F80s+tgdUoHf+TtJXcM6VIW2lmY261LHFAE4FFwO0Zjs0nPxV+CFZWoFzGVpqkmnUnN5jEsgGwKZUJoKS+k7vBnKamZQWQiKyEiZ8bVfUPYfNrIvZ0GZavFzpXVa9S1RGqOgJ4o1s67DjtRZICv6zooEY6F/tHfGwFcTPluI9cVeUVsHT2fJIK0CUtQOQmEF0CfEKZTK0gQGZSRgBJLOsD+wG/CdlmlVJIAFXi/iK4t+axfBxQpfE/kIujcgHkNDUtKYBERDBT8hxVvTS16zZyT5dHAX/q7r45jgPkBNCLedsnYRaZ3et0nVUxAfSPsCwUZD0cEzTFavoAnSYQzVKgMGEGsJPEsnKJY47Esqwqcn+lWACsJ7H0lVj6YcHkFQmgwHRg9+ASTBiJlSgoJw6XoZG+i8VzuQBympqWFEDAbthNZS8ReTT87QtcDIwTkXnYPEQXN7KTjtPGFBNAN2N1ZOoVDD0ReBubuf1q4FSJ5d/yjhkGPKGRflquMY30wYwFChNmYPN5DSu0M1i6JgIPaqTlqiwXI8kE24zqAqAT7seCtgento0EHs9YUDGNZ4I5TU9LCiBVfUBVRVV3VNWh4e9OVX1TVceq6tZh+Vb51hzH6QIGYq6kV9MbNdIPgN8CByfzblWLxLIOMAG4USNdDHwXK9Q3Kak3FATIcCqwcFRIuZnhRwHbUb31BzqnwtcigKaH5WhYFhy+M5W5vxJcADlNT0sKIMdxmp6BwMtFAnWvxmYyvy5DplUpDscCoK8G0EjfAb6JVTX+bjhmE8zqUS4Auio00pexWMNjiozlTMz9tqDAvqzkC6A3yROWGXkOm8k+iQPaFliD6gXQ+hLLWlWc6zjdggsgx3EaQboGUD4rYoUG96dI6no5Uq6lhzXSx5LtGumtmJvtXIllG7IHQFdF6Pu6wI7A/RLLAxLLn8PfA8CXMRfZ7TWIvUXAh8AW4TpPlJiioyjhnOnA6PD+VRMAnZDMCbZ1Fec6TrfgAshxnEawCcUF0BhMAAGsDOxVRfvDMUtPIdfStzDBcDUwAqu+XI3LKAtjyGWh9cKsNBuFvyRzSzARNKaaCwThsgDYEtgeeLzq3poA6h/aGgn8i1xaeyUkAmibGvriOF2KCyDHcbqVEFsygFQKfB4dWLr5Ukwc7B4qJVfCcVgxwN/m79BIXwVOBT4PnIJZUHaqsP2sdJBLnf8IOEgj/TeN9N+Ag8K2JVg1544arrMAy5xbjdrEXDoOKJkBPuu8ZGnmY59f0TigjBW6HafLcAHkOE53sx5WlLCgBSiVbn428CusSvKv89KziyKxrIpNWHpziPspxHXAQ1ia/PpU6WorR6nU+SrT6ouxAJugFWoTQP/Eap/tg8UTVeP+ItQzWkARAZSq0H0+XfTeO045Cs374jiO05UUS4FfRhADDwJILIuAc4CPJZaTMsS3HIgF7xbNrNJIVWLpwLKc0i6oWkRIsWstG0sl+yokHUT9VLWNhPdlOnAA5rKrSgAFSmWCjcHcm0KuQnfd33vHKYVbgBzH6W7KCqA8IuDHWAbXTzJUiZ6IuWDuK3PcH6mfC6rRJALoWY30/Rrbmo6JH6iDACryeT1CLjbqM3r2e+/0UFwAOY7T3VQkgILF53TgZ8B3gGuKxY5ILFthRQ+vKWcpqrMLqtEkAmhxHdxJSRzQ21gwdLXMxWKSCk1uuxu5QPdrevh77/RQXAA5jtPdDMQClDPPsxfEzMnArcDRwAXAtAL/7I/Fgm+vy9hupZWdm5Vk0uZtqT2mZtWwXKvGtpJMsE5usFAb6L+wuRoXYiLJcbodF0CO43Q3mwALK61VE45/iFx2WB+sqvNOABLLipg4ujMUIGwndsFcSStQQ0p9YHRoq6b0fIoIIOBELEbrQmAOVgnbcbodF0CO4yxHF6coD6R4Cnw5ppFLK/8US6d/VGL5HfATzN3yQD062cPowCpK1yOeqV5tLcRirJbVApJY+mKlB+7QSB8hCKCsGX6OU0/8S+c4TieC6JmGuZk6ukAElaoCXZK8uJ09MGvS+VhF5ZPDYVG7pVXXM56pXm2F+kHz6GwBOgGrjH1BWJ+DucAGVNtfx6kWT4N3HCefMVhqcpKi/DuJ5VhgajVTLKQJbqqNqFIAQcHU8XNCptH36eKU9mamjin19WxrLjY9BxLLKsBp2PcoaXt2WG5H9VZBx6kKF0CO04QEC8YYoKMBAbod5DJ0PsVE0N3AfRLL2Vh8SLV9649ZnqsWQEW4A8sQW4men9LeSswF9pdYVsIC1DcEDkvtnxOWg4HJ3dw3p81xF5jjNBlNUCX3ESzQeDomdDbFsna2Be7HYmx+WGXfKq0BlIkWS2lvJeZiD9qDsFIGfyVVn0kjXYTNXu+B0E634xYgx2k+xmAZTiuE5Ri6150zDLs3XJ4SEj+TWCZhM6l/MWyrxtXUJQII6usCcupGkgn2Q+yzP6GAG3U2LoCcBuAWIMdpPjowC0x6vTsZGZadqgBrpB9i/8g+STZRed82Ccu6CyCnKUkE0ARgFnBXgWPmAIMzVPh2nLriAshxmoxgyXg0rApQc00biWVCBWntI4EXNdJXivRtDDbVxCdUHrg6EHhXI/1Xhec5PRCN9E3g3bD6+yJB9HOAdbBJch2n23AB5DjNySZYHBDAMbU0JLEcAfyB7DFFIykxB1QQQeOx+8cvK3xyrzoF3ul5hO9a37BarDxBOhPMcboNF0CO02RILOsD6wO3A/cAx0gsvUqfVZIk66ZslWCJZT1gc8pMgqmRzsdmaN8POLiCvrgAai/GkMsoLPbdSzLBXAA53YoLIMdpPoaE5RPAJMwaNLaG9lZPvS6XIl4w/qcIVwAzgZ9LLOtm7IsLoPaig/JVpRcC72Op8I7TbbgAcpzmIy2AbgXeAiZW01CYYmAH4IOw6dgyKeIjsTo/D5drWyNdEvq1NnBphr70wSxbLoDahCzlCUJckM8J5nQ7LoAcp/nYEXhdI31dI/0Y+B+smFxWK0ua7TGBcklY37DM8SOBJ0LGV1k00seBi4GvSyzjyxyeTHfgAqiN0Egf1EgvKiO8XQA53Y4LIMdpPoZg1p+ESVg15iOqaGt0WN4API0FLxckWIt2IZv7K835wD+B6ySWUvNweQq8U4w5wMYSy5qN7ojTPrSsABKRa0TkdRF5MrVtHRG5W0TmheXajeyj4+QTgp23JyWAgpXlIWBiFbVSRmOC43lsqoE9JJaVixw7CFiTCgVQsFJdhlmXIopnmiVFEH3OJyefJBB624b2wmkrWlYAAdcB++RtOwOYqqpbYynGZ3R3pxynDFsAq9DZAgRmBRoCjMjaUBBLo4HpIc5iSmj780VOqSQAOp91sWyf9GSk+SQCaGEV7TutjafCO91Oy06FoarTRWSzvM1fJXdjvh7LSDi92zrl9CgaNCFpEgD9eN72/8OsLBMxa1AWtsKsMtPDegeWkTMeS6/PZ1esaN0/s3d3GUnbfSheIXog8IZG+lEV7TutzQLs++OZYCWo5p7U4ImVm5pWtgAVYgNVq24blus3uD9OkxJuGtOoftLPahmCCYjZ6Y2hcvJNwGESy6oZ20rif6aHNj7AJjItFgc0EnhII11aZH9Rwo11T+AVYH6RG62nwDsFCRmFc3ELUFHCPeheKrgnVXNOO9FuAigTInK8iMwUkZlAv0b3x2kIp2PWjF6UKR5YZ4YAzxTJwpoErAEclLGt0cAiLPg5YTIwRGLZKH1gEFU7Up37C1gmgi4CtpVYdipwiAsgpxQ+KWpp9gJWprJ70lFVnNM2tJsAek1E+gOE5euFDlLVq1R1hKqOAN7ozg46jUdiGQiMS20qVzywnuRngKW5H5gHHJexrXT8T8LksPxC3rHDsZtk1QIocCPwMYXrFrkAckoxB9hCYlml0R1pUt5Jvf6MbPekoVWc0za0mwC6DVPEhOWfGtgXpwkJgcNXhtUfh+VlWXznEssoieUciWUviaVv3t8e5SYjDTf+rSgigIKQuQbYXWL5aZm2BgKbkYv/SXgCeI3lBVAtAdDpPr4F/BE4Ip1tJrGsDqyFCyCnOHOwIPpBje5Ik7Id9nDxHlarq+Q9SWLZGftdX4MVU11EbpJlhxYWQCLyW+BBYBsRWSgiE7GCbeNEZB72hH9xI/voNCWHAl8CzsbcYA8DX5NYSiYMBDFyH/ADLMPwvby/DspPRjoY+00WswABJGUdTinT1u5heX96Y4jvmQKMC3V/EkYCz2ukr5W4dlYmYcUXJ6S2eQq8Uw7PBCtC+K1OAO4EYmBEhnies4C3sXvFIVgh0vO6sJs9jpYVQKp6mKr2V9WVVHWAqk5S1TdVdayqbh2WbzW6n07zILH0A/4b+Afw38Hicj6wJfC1MqcfhPnYAZYCfwG+G/7+EraXm4w0PQVGMZIg6VLp5mDur3dZPpsMzA3WD3N7JZScAb5C7gWeo7MbLBFAbgFyijEX++24AFqekcBGwB+AXwNvYgKnIBLLjljW8xUa6bsa6VTsweRUiWV4sfPajZYVQE7rElxNJd1JVXI55qY5TiP9LGy7DbO6fD/PYpLuzwpYgCLYpI8fAz/USH+ikf4Ey8BYEvaXiicaAnwEzC/Rx47Qfnq9EKOBB1LjSHN3WI4P/d8Qq9JcFwEUrEzXAmMlls3DZhdATklCQc1naeJU+C6895TjAOzecbtG+j5WEuNLEsuwIsd/H7M8/yy17buYG2ySxLJSwbPaDBdATo8i3Hg6KO9OqrTdLwKHAxdqpOkqzEuBC7Cb8v5FTv8GFmx4IQUmfQyv/yOs/riE734IMLuIaEm3tRfwFCaWZucfI7Gsjz1F58f/JG28DjxCLh2+LvE/eVyHWaqOCesDw/rLdbyG03o07ZxgKTd3Xe89Ga4rwIHAVI00CYT+OfAvCliBJJZtMJfXL0NMHgAa6dvAidi96tSu7ndPwAWQ09PYG5sXq5w7KTMhQPfX2M33wgKH3IRlX52dPxWFxDIA+BHm9jm7xKSP12IVkAulhyeUygBbRmj/68DqwDcLHJJUei4ogAKTgVESyxqYAFoCzCp37axopC9gsUbHhOk9BgKvaKSf1usaTksyGxhULuauQeyF3XPqdu/JyFBgc+CWZEOoC/Yz4ECJZfu8488AFgOX5jekkf4Bc6OdJ7G0fbC5CyCnp5H+ztac1hme4iZjAYITgxm+E8EicyEwDPhi6lwBfondDI/PSzfPb2Mplh01XmLpW6Af62FVm8sKoNDeLCwg8jsSy2p5u0dj1qGHSzQxGasEvycmgB7rggrNk7D3dRyeAu9kYw72e9qy0M4GuqDAXEppOrrpugdgsVH5WctXAB8AZyYbJJbNgCOBq4KltxAnYfeH30ks389/LyWWUazOhvXpenPjAsjpaeyB1W9S4MZaSrunqj2PwsRUKW7EJhQ9J2UFOgT4CnCORloqbifhFqwo2RcL7MsSAJ3P+Vgw8/F520cDD2qkn5Q492/A+6EvO1Nf91fCbVgdreOwGCMXQE45kklRl3ODNUFV48GYcHgcu188203XPRCr57UovVEjfQMr2XGYxLJV2Hx66NtPijWmkb6CPbgNxe4h90ksP5dYviex/By4j75s3AXjaDpcADk9BollS8xikWRq5Zt+K2lrKFYfo09q85hixwfXzSXYfFl7SizrYibomdiTWBYewIIQDyiwr2IBFMTfvcB3k5o7Esua2I2tlPuLII6mAUdgrrS6C6BgTbsB2A/YFE+Bd8pTVAAB/06DqhoHN+7+wO3AwZgb/pRuuO522HtxS5FDfooFR58hsWwMHAtcq5GWm3D4fTpnk56I3d9OJJfN2vK4AHJ6EsdgpuDrMBfOzhLLOpU0ILFsJ7H8HgsC3hi7eSwhW7Xna7G5rs7CsjDWxtxmS0qeFQiutFuBL6eLBAaGYNaSSuvwXAD0JxdsvBt2UyspgAJTgMR91hUWIDA32EqY0HQLkFMSjfQ9LFauUyaYxDIEc+0kLKV7qxp/DtgAuEUjnQv8Djix0vtPFSQPS38stFMjfRW4GivsexkmDi/J0G4HFie0BLNq7YndC/YM60Xd+a2ECyCnRxCCIo8G7tJIX8IE0ApYUHSW8w+QWGZhKe1fxEy/m2AuteUytwqhkS7GqkPvhd2Mb9BIC9XZKcUtQF86T7UBIQC6VBxREaZhBT/PCKmtozExl0XQJNNiLAbWrfC6mdBIn8Iy1gB8igMnC50ywSSWbYF7MKvFwZgLfF43z2x+IFZ+4s6wfiH2O/6vLr7uAcDfwz2vGD/CHnoOBqZopAvKNRreu7Hk7n0dGumHGmkHMJb32yNb0wWQ01MYj1lsJoX1f2BpoPlTOiyHxLInJjyGYU+Oh2ik52ik72ikD5bI3CpEupT8oVXEIUwL/V7mBgt1hLansvgfYNn0GImYOwITQA8VmUw1n37Yk14f4J6uiKkIbW4dVs/12aidDMzGJtRdIcS23It9T8dqpDdjFo7tC2Q/dQkh5u8ATFy8BxBKZdwKnBwyKbviuptjxUqLub8S0vE6e2b9jRW792mkD/Ier1bW256JCyCnpzARe/K7HSC4ne7Bsqqk1Iksnyo+tOBR2diVXMB0xXEIIfbmNuCrqWJkm2Pm54oFUOAvmEvvbCygOYv7C6zvSylfVboWxmBmebCss664htNazMF+D5/HppXpDeytkT4d9t+AWTkLTbjbFYzAshjzhcgFWOHUQqUo6kHykPSHMseNSb3231gFuABy6kpXpKlKLBtg2Va/yctsmoKlWZcrnLYV9gSZNdanFB3AJzW29QcsfmiPsF5NBtgyUlagLbAbYLH013w6qH0szXANp7VIAqHvwX4n4zTSZA48QjbUbcCREkvvbujPAdj398/pjRrpTOAubHqJ/FIU9bruoxppuWyzDvw3VhUugJy6IbF8Dct0qnea6pHYP/ZJeduTGJbxFCEU+xqKpYtmivUpRQHfeTVtTQY+xOIKICeAnip8eCZeJRe4eEGW975OY2n4NZyWY9WwXAmz/uQnDIDdC/phGYZdRqoK87R0VeUUSSmKb9T5uhthgdfl3F/+G6uBZqy26fRAQhzLJeREdeJSqenHGG5AE4G/aaT/TO/TSJ+XWJ7GBNBlRZqYiLmsfhgyJmom3GBqEVEfSSx3AhMklpMwAfSEi4XhAAARDUlEQVRsmOOnWvbA3FnpFOGyfax1LFnojms4LUUSq7cC9n0ew/LfnylYtthE4OYu7MsOWAzbclWVATTSv0osHVgpil+FRIl6kEy7U879lfTDf2NV4BagNqEa11SF5/wnVusliY9RMphiM1xjFLAty1t/EiYDexRIKyfE2BwF3FEv8VNHbsHSakeRcQqMMnTgZnCnNejAMq6KfpdDSYnrsBjAgfn7s5Dx/nYAdi+7tcQx52Mztf+2jlbvY7CaYWvWqT2nAC6A2oBqJhCVWMZjE/+VdWdJLJsAF2OzjO+OuXIUq2tTrl/3lunXcVj66++LNDMZM5HvXmDfvpjIKCaeGskdmGA5HHvCrEkAuRncaRUq+C5fiwXwH13pNTLee8DcXw+UeYD6ELNY7Q/cW6sIklgOxwKv+5Xpm1MjLoDag2+Tm0B0FeC0VAZSJySWNSWW87B5Z1bCTNC9KZJZEFxUV4a2jw83q3FYMa3/F1xjxTgEEy9Jvy5MFxYLk5QeAvyuhHvoPkxIFIoDmogVLryzwL6GEtJpp2BPer2o3QJUNK3VcXoaWb7LITj4XuDYMveZQowld+9ZGSsA2AmJZWvMOltJFtbKwKUhhqciJJYtJZYbsCw36NrsTAePAeo2goofA3Rk/QdVzTkF2jgYOAh7QklKnx8AzA5C5zmsdszfsUkxv4dlXkzDgvD6YP+gi01jcBhmaTlFI30ObK4ZieVUrELpccBVBfo1CJvRXEPfwOJYFkgsPwUux2Y1Xo0SRf000g8klgcwAXRaqv3+oV8/zlqpuQHcAnw5vPaHEcepnKuB/8WKk95TwXmbhWVyTxwmsUheIdKsaegdmMuud2hvZ2B+mFfrR1gW6hjy7uOp+/ts4EvYNBafhPEcgIkfd2d3IaIVF55tL0RkpqqOqKkN+6In9Sw+IYOLImWiXSnrOQXa2A/7JzsDMyePxH5M/TDT747kMoeSWjp3AudqpA+HPhyAxdEosEc6EFli6YelrM4Hdgt++WSfYDekEcDgdCVTiWULrFZNb6yS6uahX+8DP8BMyf8C1gj9+qjU+CWW72EB2AOS60gsZwAXAYM00nkVvG3dRnAz3hVWS47RcZzlCbF/LwOTNdLDMp6zPVY3axp239kBm2fsp8B3ExEksfwDEI105wxtLntYxcpQnIsVJl1Mzvr+KfZQ908srvHisE+weKdfAReGB8iaH35roR7/93oCbgHqYsKkmReRmwYgcSeV+1IfRS79sw9mzcj8Q5BY9gFuAmYB+2qk72KCKtl/B/A/mAUHTOD8WiP9z+SYJLNAYrkaczXdK7GM1kifCYdcjgXpHZcWP+FclViOx1w7v5BYJoRtm2BicBVgzwJTSUyQWHYOfUsCAMtlNU3GBNA44Logvo7FZlBuSvETGE7nCQnH4JkcjpMZjXSxxHIj8A2JZZ0iqerLCJOaTgLeBY7QSBeF+8VbwKnYg8g54T61M3Bmxn7kZ2EdJbFcjM0ZlpS56EPhbFUFLtVITy/RntMFuNm9i0jF0izAXEyJQOhF+eDgkVjtGw1/KwDfkVh+ILGsleHae2GT580G9gnipxMa6VJsNvOPQt8WA78p1F6owLo3Jt6mSiybSiz7YgG8F6aLlOWdNx97EvoqcFDwi0/FXGxfKDaPlkb6EBbYmEzWV84M/Dg2iWgSB7Q7FljcjMHPaTrIPkbHcQozCRMXh2c49iTMEn5yKKiYFBI9GXOnnS2xnAVMCMdnSkMvhEY6BzgB+41/hrnJvoFlfn6DXKbbYkpnmTldhLvAylCpKTDMO3U6Fj+zOlaj4jzMnfMVTNisgbk7ZhY4fzhmqXkDOAUzzz6H/SAPBt4B/g8rfDcl3zwqsZyACZsXgV2TH3mJ/mY2tUosw0LfPsRic94CttNIPy5xzopYfNEW2I99Naysfdmnmwr79htyWV/XYG60/hnnxGoYjTZ1O04rILH8E7uvHljCVb45NhlyB/Dl/ImHg3XoWuwe/S72cDih1t9lsd94M//228UF5gKoDFm/CMEXfRGWcQWm+CdqpNfnHTcQi39ZE3MBPZbaNwTzS78PjNZIX8g7dygmbj6f2ryUziRWvS6JKZFYjiVnWfkYG0M5cXIkOetSpnOq6NfhmNtsHFYm//q0O89xnNYkCIn7MDfyEmB/jfSOvGMEc5WPArbPv7emjlsRi8sbi1nfF9OGsXntIoDcBVYjEkvvYHV5BhM/iaJUrDhWJzTSF7GMhQ+AuyWWwaGdbbGg4eQHt9wPVCN9FAtSTtxpS7Ef/oXh7z5ygqir0ic3oLM7L8s1BpDrV9ZzKuXusPwlFl/U7O4vx3Hqwxhy/8tWBP4osVwc4i8Tvo49HJ1RTPzAskmWp9H1kwQ7TYALoHKszob5hahCBdHvSyw/wCL6fwU8j/mXy8Z0aKQLMBH0GRZT820sU2tFTPzML9GjDnIVfz8GztJIz9FIzwHOokwF1TqQvn7Wa3R0db800teBp7HYn2eAh+t9DcdxmpIOcvekxZib/ntYSY3zQimQK7FYwSsztHcvXX8fdZqAtnOBicg+wBWYJeJqVb245PEbiXICnwF/A97GAng/F84H+6d7CnBXyHKqJG5lMPBXIAlsXgzslTFFvuA1usOv3KiaRhnan46JyE+xlP22Mls7TruSf38Jqe4xuQmHIeP9tVB79e9xc9MuLrC2EkAi0guYi5lCFwIPAYep6uyi55gAAqso/BrmAuofdn8GnKORXlR1n2K5AvgWuVoQ59bSXrsisZyJTdvRC38fHccBJJafASfi99eKaBcB1G4usF2AZ1T1WVX9BMum+mqZcxQLKD5QIx2GPVF8hP2YPqF28+j/4anQ9aADnwzUcZzO/C9+f3WK0G4CaGMsPTxhYdhWnPd5mVQWQL0nnfRJLOuDv4+O4+Tj9wWnFO3mAjsYGK+qx4X1I4FdVPVbeccdDxwfVvup6mbd2lHHcRzHaRDuAmtNFgIDU+sDsHlkOqGqV6nqiPAFKFm12XEcx3Gcnke7WYBWxIKgxwIvYUHQ/66qT5U45z0s06td6Ud7i8B2Hn87jx18/D7+9h3/Nqq6eqM70dW01WSoqrpERE7CKoL2Aq4pJX4CT7eDKbAY7WIKLUY7j7+dxw4+fh9/+45fRJabpqkVaSsBBKCqd2LVlB3HcRzHaVPaLQbIcRzHcRzHBVAGrmp0BxqMj799aeexg4/fx9++tMXY2yoI2nEcx3EcB9wC5DiO4zhOG9IyAkhEVhGR+8J8X4jIXSLyjojcnnfcWBGZJSKPisgDIrJV2P4fIvJEavvgsH2ciDwc9j0sIntl6Mt5IvJSaOtREdk3bB8iItfVffDUZfxHi8iiVJ+TYpFDReRBEXlKRB4Xka9V0KeDRERFZERYb9rxh32HiMjsMNb/DdvaYvwiclnqs58rIu+E7U0//jqMfRMRmSYij4QxJr/Xin/7qWudFsbeL6x/WUTi+o2607VqHf+mIjI1jL1DRAaE7U3/2Ye2s45/rzD+J0XkerGyKIjx3yLyTBjn8LC9Xca/bRjnxyJyWur4geF3MSe8BydX0KedReQzETkorK8nInfVZ8R1RFVb4g+b8O7k1PpY4CvA7XnHzQW2C6+/CVwXXq+ROmY/4K7wehiwUXi9A/BShr6cB5xWZN89wCZNOP6jgZ8XaHcQsHV4vRE2KexaGfqzOjY7+9+BET1g/FsDjwBrh/X122n8ecd8CysR0SPGX4fP/irgP8PrwcBz4XXFv/1w7ECs1MbzWCV5sMk4HwFWbbbPHrgJOCq83gu4oad89lnHjz3svwgMCus/ACaG1/sCfwmf0a7AjDYb//rAzsAFpP5vYZN+D0+NaS4wOEN/egH3YtnWB6W2XwvsVu/x1/LXMhYg4HDgT8mKqk4F3itwnAJrhNdrEipBq+q7qWNWC8ehqo+oalIt+ilgZRHpU0M//wwcWsP5xahp/MVQ1bmqOi+8fhl4HVgvQ39+CPwIm4gwTbOO/xvAL1T17XD+62HZLuNPcxjw29BOTxh/rWMvdk+o9rd/GfC90G7SJ8Um4vxyhvMrpdbxDwamhtfTCBNE95DPHrKNf13gY1WdG9bvxia2Bhvvb9T4O7CWiPRvl/Gr6uuq+hA2WewyVPUVVZ0VXr8HzKHc3JnGt4BbsPcrza2hr01DSwggEekNbKGqz2U4/DjgThFZCBwJXJxq50QRmY99ef+rwLkHAo+o6scZrnNSMJteIyJrp7bPBHbPcH5m6jV+4MDQ55tFZGD+iSKyC9AbmF+mP8OAgap6e4HdzTr+QcAgEfmriPxdRPYpcJ1WHn/S1qbA5tgTXP51mm78dRr7ecARYfud2A08n0y/fRHZD7MUPVZgd7N+9o+REwMTgNVFZN286zTdZx+ul3X8bwArJS4p4CBy0yKVnSS7xcef5TqbYRbRGWWO2xj7Dv2qwO66j79WWkIAYSXL38l47CnAvqo6ADPJXZrsUNVfqOqWwOnA2emTRGR74BLghAzXuBLYEhiKmU1/mtr3OmZOrSf1GP+fgc1UdUfMVHt9+iQR6Q/cAByjqkuLNS4iK2BPwKcWOaRZx78i5gYbg1lArhaRtZKT2mD8CYcCN6vqZ+mNTTz+eoz9MMwdNABzh9wQxgFk/+2LyKrAWdjM44Vo1s/+NGAPEXkE2AObJmhJclITf/aQcfzBAncocJmI/AOzkCRjlEKnJC/aYPwlEZG+mEXn23mekkJcDpyef/8IdMX4a6PRPrh6/AFrE/z2edvH0NkPuh4wP7W+CTC7wHkrAP9KrQ/A/J8V+y+BzYAnU+tDgAeafPy98sa/BjALODhDX9bEnjaeC3+LMVP7iGYeP/bEcnRq31Rg53YZf2rbI8Dn8rY17fjr9Nk/hT21J/ueJRcDlvm3H8b2emrsS4AXgA3D/q8A/9Osn33Y3hdY2BM++0rGX2D/F4Dfh9e/Bg5L7Xsa6N8u409tO4+82FVgJSye7TsZ+7MgNf73w+9h/7Bv9fR3qxn+WsICpBa30UtEVi5z6NvAmiIyKKyPw/yaiMjWqeO+BMwL29cC7gDOVNW/phsTkd8E0yh52/unVicAT6bWB+Wt10ydxp/u836p7b2BP2I+8pvSjYnIRSIyIa8v/1LVfqq6mapuhgUC7qeqydwyTTl+zD+9J4BY5s4g4Nk2Gj8isg12Q30wta2px1+nsb+ABY4iItsBKwOLKv3tq+oTqrp+auwLsSDSV8MhTfnZi0i/lMXrTOCasL2pP/twzazjR0TWD8s+mJU/cdPcBnxdjF2xh79X2mj8xY4XYBIwR1Uvzdt3kti8mvn92Tw1/puBb6rqrWF33cdfM41WYPX6wz6ovVPr9wOLgI+wG9H4sH0C8ATm9+7A/KcAV2BPgo9igYDbh+1nAx+E7clf8nT4KKknx9S1bwjXeBz7cfVP7fs58JUmHP9FYfyPhfFvG7YfgQXHpcc/NOy7HRhVpl8ddM6EaNbxC+YSmB32H9pO4w/7zgMuzmu36cdfh89+MPDXsP1R4Athe8W//bx+PUfIAku9X0Oa7bPH4kHmYZauq4E+PeWzr3D8P8ZE39OYOyc5XoBfYPE9T5Cz2LTL+DcMx72LudMWYpavz2OuwMdT4983NZbDyvTrOjpngZ0GfKve46/pvWt0B+r4JRhGSN/spuutAdxU4Tl9sKeCFXv6+MM1J/v4ffyNHn8P+e1vAEztov607Wfv42/Y+G8Held4znRCmZFm+WupqTBE5Fjgei0cgNVwgpttY1Xt6KL2ffw+/rYcfw8Y+87Ap6r6aBe13+zj9+9+e49/PSyO7tayB3cjLSWAHMdxHMdxsvD/ATwx3fPTYbShAAAAAElFTkSuQmCC'></td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row5_col8" class="data row5 col8" >8/10 0.02 2%</td>
</tr>
<tr>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row6_col0" class="data row6 col0" >sibsp</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row6_col1" class="data row6 col1" >6</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row6_col2" class="data row6 col2" >int64</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row6_col3" class="data row6 col3" >Number of siblings/spouses aboard the Titanic</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row6_col4" class="data row6 col4" >0<br/> 0%</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row6_col5" class="data row6 col5" >7<br/> 1%</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row6_col6" class="data row6 col6" >[0.0, 0.0, 0.0, 1.0, 8.0]<br/> mean: 0.52 std: 1.10<br/> cv: 2.11 skew: 3.69*<br/> log skew: 1.67</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row6_col7" class="data row6 col7" ><img src='data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAkAAAACQCAYAAADgO9QwAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADl0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uIDMuMC4zLCBodHRwOi8vbWF0cGxvdGxpYi5vcmcvnQurowAAEGZJREFUeJzt3X+wXGV9x/H3l5vEYEC0BTuSoIkjcg0oiY0/sa0/aKXqbWtnrOjU6Q9rrNMq6ei0xbY4aDvjH/6s01Gios5odTrItC4VlY5atVUkQNCErG0EhQTagCIQpYQk3/5xzpJ7N3fvr+zu2c3zfs3snJzds89+c2+eez95zjnPE5mJJElSSU5ougBJkqRhMwBJkqTiGIAkSVJxDECSJKk4BiBJklQcA5AkSSqOAUiSJBXHACRJkopjAJIkScUxAEmSpOIYgCRJUnEMQJIkqTgGIEmSVBwDkCRJKo4BSJIkFccAJEmSirOs6QJGXUTcBfyw6TqkMfCEzDyt6SJ6sS9LCzbSfblfDEDz+2Fmbmq6CGnURcS2pmuYh31ZWoAx6Mt94SkwSZJUHAOQJEkqjgFIkiQVx2uAmtCOzTP2J3NrQ5VIklQkR4AkSVJxDECSJKk4BiBJklQcA5AkSSqOF0FLUm1qaupG4DRg94A+Ynur1doyoLYlLYIBSJKOWHdC5ClPXPOz1f1ueO++lTzw4ES/m5W0REUFoIhYCXwNeATV3/2KzHxbs1VJGiUrVhzmogtv7Xu77//MOnbfvqrv7UpamqICEPAg8MLM3B8Ry4FvRMTVmfmtpguTJEnDU1QAyswE9te7y+tHNleRJElqQnF3gUXERERsB/YB12TmtU3XJEmShqu4AJSZhzJzA7AGeGZEnNN9TERsjohtEbENOHXoRUqSpIEqLgB1ZOZPgK8CF8zy2tbM3JSZm4C7h12bJEkarKICUEScFhGPrv98InA+0G62KkmSNGxFXQQNPA74RERMUIW/f8rMqxquSZIkDVlRASgzvwNsbLoOSZLUrKJOgUmSJIEBSJIkFcgAJEmSimMAkiRJxTEASZKk4hiAJElScQxAkiSpOAYgSZJUHAOQJEkqjgFIkiQVxwAkSZKKYwCSpCNOfOihaLqGRZuamnrf1NTU+5quQxonRS2GKknzmDic4xeAgA1NFyCNG0eAJElScQxAkiSpOAYgSZJUHAOQJEkqjgFIkiQVxwAkSZKKYwCSJEnFMQBJkqTiGIAkSVJxigpAEXFGRHwlInZFxM6IuKjpmiRJ0vCVthTGQeDNmXlDRJwMXB8R12TmzU0XJkmShqeoEaDMvDMzb6j/fD+wC1jdbFWSJGnYigpA00XEWmAjcG2zlUiSpGEr7RQYABFxEvBZYEtm3jfL65uBzfXuqcOsTZIkDV5xI0ARsZwq/HwqM6+c7ZjM3JqZmzJzE3D3UAuUJEkDV1QAiogAPgrsysz3NF2PJElqRlEBCDgPeA3wwojYXj9e0nRRkiRpuIq6BigzvwFE03VI0riYmpq6DtgEfKvVaj2nz23vAM4Gbmq1Whv63PbrgK3Aa1ut1uX9bHtcTU1NXQpcAlzSarXe0XQ9TSttBEiStDib6u2zB9D22fX23AG0/cF6e9kA2h5Xl9TbSxutYkQYgCRJs6pHf6bvf7OPbe/o2t/ex7ZfB0zUu8umpqb+sF9tj6t69Kcjpqam/qaxYkZEUafAJKkpd92zAmDD1NTUVwfQ/AZg/wDa3dS1389RoLO79vs5CvTBrv3LgNJPg13StX8pUPRpMAOQpOOWc3oVa6Jr3991Ryv+elj/UUg6bmXmVqoLYYmIbU3WctpjDnDv/uXbW63W8/vd9oBGlcbZIWaGoINNFTLCsukCmuY1QJKkXrpD47f62PbOrv2b+tj2G7r2X9/HtsfV27v239ZIFSPEACRJmlWr1XpG137fboNvtVrndO337Tb4Vqv1YapRIICD3gYPrVZreuBJb4M3AEmS5tYZBern6E9HZxSon6M/HZ1RIEd/juiMAhU/+gNeAyRJmkP3KFCf2z5n/qOW3PaHgQ8Pqv1xVI8CGX5qjgBJkqTiGIAkSVJxDECSJKk4BiBJklQcA5AkSSqOAUiSJBXH2+CHqR0BXAWcDlwJ/G+zBUmSVCYD0HBtBF5CtQbLWcDFwAONViRJUoE8BTZcrwYeAi4DTgTObLYcSZLKZAAalnacAFwIfAH4LnAAeEqjNUmSVCgD0PA8D1gN/CNwEPhvDECSJDXCADQ8z6u3V9fbXcDjgFOaKUeSpHJ5EfTwbARuYTLvpR1QBSBY6ihQOzbP2J/MrcdSnCRJJSluBCgiLo+IfRGxY8gfvQG4cdr+Xqo7wNYNuQ5JkopXXAACPg5cMNRPbMfJwJOA7dOeTeBOqjmBJEnSEBUXgDLza8CPh/yx59bbG7uevwM4vZ4gUVLzDp0Q2XQNS7Gdmf/BkjQPrwEajg31tvsH1F6qi6Mfi7NCS6PggeXLc0XTRSxWq9Xa0nQN0rgpbgRoISJic0Rsi4htwKl9aHIDcDfViM90nf1z+vAZkiRpgQxAs8jMrZm5KTM3UQWXY7UB2M5kdo+tdwLQ2X34DEmStEAGoEGrZoBeTzX7c7f7gP04AiRJ0lAVF4Ai4tPAN4GzImJPRLx2wB/5eKp1v27u8fodGIAkSRqq4i6CzsxXDfkj19fbuQLQ02lHzHKKTJIkDUBxI0AN6ASgXT1evwN4FLBmOOVIkiQD0OCtB+5kMu/p8freeutpMEmShsQANHjr6X36C7wTTJKkoTMADVI1w/N8AehnVEtiOAIkSdKQGIAGazVwMnMHIIAdGIAkSRoaA9BgdUJNrwugO3YC6+s5gyRJ0oD5C3ewOougfmee43ZQzRW0brDlSJIkMAAN2rnAbXPcAdaxo94+dcD1SJIkDECDdi5w0wKO2wkkR0aMJEnSABmABqUdK4GzWEgAmsz9QBv4xQFXJUmSMAAN0tnABAsbAQK4nqUFoABWLOF9kiQVywA0OJ3TWQsNQNuA02nH4xbxGY8G3gK8m3Z8gHacspgCJUkqlQFocM4Ffgp8f4HHX19vFzoK9EjgrcAZwHeBNwAfWkyBkiSVygA0OJuAm5jMwws8fjtwmIUHoN+kWkT1XcBW4FLgQtrxW4stVJKk0ixruoDjUjtWAc+kCicLM5n7aUebKjjN1/5TgV8B/h24rX72ncBvAx+gHVczmQ8usmpJwIEDJ/D+z/R/Sq69+1b2vU1JS2cAGoznUn1tv7rI930bmKIdE0zmoTmOuxR4APiXh5+ZzIdox18AXwR+j2pUSNLi3Ho447Tdt6/aPaD2tw+oXUmLZAAajBcAB4H/WOT7rgZ+H3gW8J+zHtGO9cDLgX+lWkh1umuoQtTFtONjTOZDi/x8qWitVmtj0zVIGg6vARqM5wPX1fP7LMaXgEPAy+Y45i+pgs+Xj3plMhP4W2At8OpFfrYkScUwAPVbO04CnsHiT3/BZP4E+Drw0h5tn0UVbC4DeoWrq6huvX8r7ZhYdA2SJBXAANR/L6c6tfjFJb7/KuBptOPxs7x2KfB/VBc8z+7IKNCTgVcssQZJko5rBqD++2Pgv4CvLfH9/0y1LtibZjzbjk3AK4H3Mpn75mnjSuBm4B31khySJGkaA1A/teNpVHeAfageiVm8yfw+8HHgjbRjbd3uKcCngTuBdy+gjcPAFuBJVNcMza8dm2c8JEk6jhUXgCLigoj4XkTsjoiFhYOFaEcAfwU8CHziGFu7hOpi6E/SjpdRjQqtA15ZXyc0v8m8hio0XUw7nnWM9UiSdFwp6jb4iJgA/gH4VWAPcF1EfC4zb+5D868Hfge4hMn88TG1NJl7aMcbgL8HWsB9wOuZzK8vsqUtVLfUX007zmcyb5j1qHYspwpYTwZ+AVhJOzZSrVD/FWDHIma0nt7uzJGkyTy2uYlmG5k61jYlSUUqKgBRzc68OzNvAYiIz1AtKbH0ANSOR1GN2Gyhmsfn7469TGAyP0E7rqKaU+jfFjzyM7ONfbTjfKo7y75NOy6va/wR8BjgqcDz6seq+l33Uk2yuBb4+fq5u2nH14FvUM1ttBu45+FQVI1+rQRWA2vqxxnArwE/R7Vo60Ha8WJgL/AD4BaqddJuPWq6gHacUL9nLVUoO7Pengc8FlgOHAB+VP/9dgM7qb6PtwD3LfoUZPWZy4HDx+X8SUe+RyfWj0cCK6imVLgfuN/ZwyWVpLQAtBq4fdr+HqoRkmPxTqoLnz8KvGVJIyW9TOaPgCuOsY1baccG4O3Aa4HXdR2xk+qao+VUF2/fX79va30n2gvqxy9R3eHWcYh2/Lh+30nM/m/pp8A9wE/q159CNfp28oyj2nE/1anDB4FHUIWm7tOzt9XtbauPW0kV0DZw5M67jgO0Y199/GGq04nL6lqXU/3i72xXAhMzPq8dh6iCwQPTtg/Unzs9WC3kz937Mct2vucW+54JjgSdE6m+P8uZTzsO0AlD1WMZVVBaBfw1k3nZvG1I0piIXOK1uuMoIl4BvDgz/6jefw3wzMx8Y9dxm4HO6ZazgO/1uZRTgbv73GY/Wd+xG/UaB1HfEzLztD632TcRcRfwwwUcOurfu16se7iO57pHui/3S2kjQHuoTs10rAHu6D4oM7cywLW0ImJbZs6/6GlDrO/YjXqNo17fICz0B/q4fm2se7ise/yVdhfYdcCZEbEuIlYAFwKfa7gmSZI0ZEWNAGXmwYj4U6pZmieAyzNzZ8NlSZKkISsqAAFk5ueBzzdcxqjfum19x27Uaxz1+po0rl8b6x4u6x5zRV0ELUmSBOVdAyRJkmQAGraBLcXRBxFxRkR8JSJ2RcTOiLio6ZpmExETEXFjRFzVdC3dIuLREXFFRLTrr+Nzmq5puoj4s/p7uyMiPh3hYrkdo9w3exmXPtvLKPfluYx6P+/F/j+TAWiIpi3F8evAeuBVEbG+2apmOAi8OTOfAjwb+JMRq6/jImBX00X08H7gC5k5CZzLCNUZEauBNwGbMvMcqhsBLmy2qtEwBn2zl3Hps72Mcl+ey8j2817s/0czAA3Xw0txZOYBoLMUx0jIzDszq/XCMvN+qk69utmqZoqINcBLgY80XUu3iHgU8MtUs4KTmQcyl7CEyWAtA06MiM4sz0fNg1Woke6bvYxDn+1llPvyXMakn/di/5/GADRcsy3FMZI/rCJiLbARuLbZSo7yPuDPqZa4GDVPBO4CPlYP638kIlbN96Zhycy9wLuolhW5E7g3M7/UbFUjY2z6Zi8j3Gd7GeW+PJeR7ue92P+PZgAarpjluZG7DS8iTgI+C2zJzPuarqcjIl4G7MvM65uupYdlwNOBD2bmRqq1yEbmWpKIeAzVqMY64HRgVUT8brNVjYyx6Ju9jGqf7WUM+vJcRrqf92L/P5oBaLgWtBRHkyJiOdUP0k9l5pVN19PlPOA3IuIHVKcoXhgRn2y2pBn2AHsys/M/8CuoflCOivOBWzPzrsx8CLgSeG7DNY2Kke+bvYx4n+1l1PvyXEa9n/di/+9iABqukV6KIyKC6rz2rsx8T9P1dMvMizNzTWaupfrafTkzR+Z/MJn5P8DtEXFW/dSLgJsbLKnbbcCzI+KR9ff6RYzBxZtDMtJ9s5dR77O9jHpfnssY9PNe7P9dipsJukljsBTHecBrgO9GxPb6ubfWs2drYd4IfKr+JXoL8AcN1/OwzLw2Iq4AbqC6e+hGnBUWGIu+2Yt9thkj2897sf8fzZmgJUlScTwFJkmSimMAkiRJxfl/I1inXwZFu8cAAAAASUVORK5CYII='></td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row6_col8" class="data row6 col8" >6/10 0.02 3%</td>
</tr>
<tr>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row7_col0" class="data row7 col0" >parch</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row7_col1" class="data row7 col1" >7</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row7_col2" class="data row7 col2" >int64</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row7_col3" class="data row7 col3" >Number of parents/children aboard the Titanic</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row7_col4" class="data row7 col4" >0<br/> 0%</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row7_col5" class="data row7 col5" >7<br/> 1%</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row7_col6" class="data row7 col6" >[0.0, 0.0, 0.0, 0.0, 6.0]<br/> mean: 0.38 std: 0.81<br/> cv: 2.11 skew: 2.74*<br/> log skew: 0.93</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row7_col7" class="data row7 col7" ><img src='data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAkAAAACQCAYAAADgO9QwAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADl0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uIDMuMC4zLCBodHRwOi8vbWF0cGxvdGxpYi5vcmcvnQurowAAEPBJREFUeJzt3X+wbWVdx/H313svXOCClPcmV1HRyTypKdiNVMwpMzPz+Gt0iBFmNPRaTQRpMdrkZDn9+KOQfo3jDX+lTGbKVMehKWfUSSqRi2GJLI0hERAEBOKnwL18+2Ot3dns7uWcu88+a51nP+/XzJ691zn77ue7zmGd/eH7PGuvyEwkSZJq8qihC5AkSeqbAUiSJFXHACRJkqpjAJIkSdUxAEmSpOoYgCRJUnUMQJIkqToGIEmSVB0DkCRJqo4BSJIkVccAJEmSqmMAkiRJ1TEASZKk6hiAJElSdQxAkiSpOgYgSZJUnc1DF7DRRcQtwLVD1yEV4EmZuWPoIg7GY1latQ19LM+KAWhl12bmrqGLkDa6iNg7dA0r8FiWVqGAY3kmnAKTJEnVMQBJkqTqGIAkSVJ1XAM0C03sPuj3FnLPOo77bOBqFvKedRtDkqQ5ZAeoVE1sAb4AvGnoUiRJKo0BqFyHAVuBRw9diCRJpTEAlWvTxL0kSVolA1C5Nk/cS5KkVTIAlcsAJM3Y4uLi+YuLi+cPXYek9WcAKpdTYNLsvaG7SZpzBqBy2QGSJGlKBqBy2QGSJGlKBqBy2QGSJGlKBqByGYAkSZqSAahcToFJkjQlA1C57ABJkjQlA1C5DECSJE3JAFQup8AkSZqSAahcdoAkSZpSVQEoIrZGxBcj4ssRcWVE/PbQNa3BKPjYAZIk6RDV1j24H3hRZt4dEVuASyLiHzLzC0MXNoVR8KntdyhJ0ppV9eaZmQnc3W1u6W45XEVr4hSYJElTqmoKDCAiNkXEFcDNwKcz89Kha5qSi6AlSZpSdQEoM/dn5onA8cDJEfHMyedExO6I2BsRe4HtvRe5OnaAJEmaUnUBaCQz7wA+B7z0AN/bk5m7MnMXcGvfta2Si6AlSZpSVQEoInZExLHd4yOAFwPNsFVNzUXQkiRNqbY3z53AhyNiE234+3hmfmrgmqblFJgkSVOq6s0zM/8DOGnoOmbEKTBJkqZU1RTYnHEKTJKkKRmAyuUUmCRJU/LNs1x+DpA0e9uGLkBSPwxA5bIDJM2e/0MhVcIpsHK5CFqSpCkZgMrlImhJkqZkACqXU2CSJE3JAFQup8AkSZqSAahcToFJkjQlA1C57ABJkjQlA1C5XAMkSdKUDEDlcgpMkqQpGYDK5RSYJElTMgCVa/lSGE3EoJVIklQYA1C5xqe+7AJJknQIDEDlMgBJkjQlA1C5xkOPC6ElSToEBqBy2QGSJGlKBqBybT7IY0mStIKqAlBEPCEiPhsRV0XElRFx9tA1rYFTYJIkTam2N859wNsy80sRcTRweUR8OjO/OnRhU3AKTJKkKVUVgDLzRuDG7vFdEXEV8HigxABkB0iaE4uLi/cCRwD3LS0tHVnR2G8G9gBnLi0tfaDnsV8H/DXw2qWlpYt6HHfIfd4JfAw4dWlp6aY+x96IqpoCGxcRJwAnAZcOW8nUXAMkzY8jJu5rGfu93f37Bhj7I0AAF/Y87pD7/E7gBd199aoMQBGxDfgkcE5m3nmA7++OiL0RsRfY3nuBq+MUmDQHug7MQbfneOw3M3ZNw8XFxZ/vcezXAYd3m1sXFxdf09O4Q+7zTuCNtO/7b1xcXDyur7E3quoCUERsoQ0/F2bmAduembknM3dl5i7g1l4LXD2nwKT5MNl56bMTM+TY753Y7rMj8pGJ7b66QEPu8ztpO17QvvdX3wWqKgBFRADvB67KzPOGrmeN7ABJKyikm1uryb9bff6P3OET21t7GnfIfX49y/t9OHB6j2NvSFUFIOAU4AzgRRFxRXd72dBFTck1QNIKCunm1mr/xPa+Hse+f2L7uz2NO+Q+X8jyft8PfLTHsTekqgJQZl6SmZGZz8rME7vbxUPXNSWnwKT5cN8K2/M69i9ObL+lx7HPmNh+fU/jDrnP7waye/xQt121qgLQnBluCqyJHTTxgl7HlObU5KnnfZ6KPvDYf8FyR2Rfn6eELy0t/Q3L3ZDv9nUa/MD7fCPwQdrw80FPgzcAlWzIDtBZwD/1PKY0z+6buK9l7FFHpM9OyMgZtB2Rvro/I0Pu87uBS7D7A0Bk5srPqlhE7O3WDxxcE7sP+r2F3DPrmroxLwN+iHYx2wtZyM+vyzgHHvt84GzgMBbywd7G1Ya2qmNlQKupb3FxMQGWlpbikZ4nzbONfizPih2gcm1muYXbdwdodCZBr58aK0nSrBiAyrWJ5TMX+g5Ao1NGDUCSpCIZgMo13gHq+3OA7ABJkopmACrXkFNgdoAkSUUzAJVrE64BkiRpKgagcg05BWYHSJJUNANQuTYz3CJoO0CSpKIZgMo1PgU2VAeozytHS5I0Mwagcvk5QJIkTckAVC4XQUuSNCUDULlcBC1J0pQMQOVyEbQkSVMyAJVrIyyCNgBJkopkACqXi6AlSZqSAahETTwKCIYIQE0EywHI0+AlSUXqu3Og2RhNeQ0xBXbY2GM7QJo3+4cuQFI/qusARcQHIuLmiPjK0LWswSi4DrEIeuvYYwOQ5s3d3U3SnKsuAAEfAl46dBFrNNkB6jMAHT722AAkSSpSdQEoM/8ZuG3oOtZoFHgeBJJ+p8DsAEmSilddAJoTowC0j3bNgh0gSZIOgYugDyAidgO7u83tQ9ZyEKOOz77uNkQHKDEASZIKZQfoADJzT2buysxdwK1D13MAo+C6nzYADdEBugNPg5ckFcoAVKYhp8BGHaDbsAMkSSpUdQEoIv4K+DfgaRFxfUScOXRNUxhNeY06QH1OgY06QLdjAJIkFaq6NUCZedrQNczAeAeo7ymwh3eAmggWMnscX5KkNauuAzQnNsJZYLfTdp629Di2JEkzYQAq05BTYKMO0B3dvdNgkqTiGIDKtBE6QKMPkzQASZKKYwAq05CfAzQ+BQYGIElSgQxAZRryc4DGF0GDnwUkSSpQdWeBFa2J3cBjgOO6r7wEOIbhFkGDHSBJUoEMQOU5l+Xuy0PdbYhF0AYgSVKxDEBl2Qwcy/Kp56MA1HcH6EHg7m7bACRJKo5rgMpydHd/VHe/n2E6QN8F7u22DUCSpOIYgMpyzMR2Msxp8PdjAJIkFcwAVJajJ7b304agHTRxK028uIcaJjtARz3CcyVJ2pAMQGWZ7AA9RBuCfpD27LAfXbeRm9jdnYX2DNou0Gtow9fPrNuYkiStExdBl2WyAzRaBD1aFP3EHmrYQrsIej/tmWDbexhT6suHhi5AUj8MQGU5UAfoobHtPgLQZtoPXwT4DgYgzZGlpaVzhq5BUj8MQCVo4nm03ZaDdYBG+uwAAdxKO/0mSVJRXANUho8D76HtAN099vXRafAjT6SJoIlt61jLeAfoVuBYmtj6CM+XJGnDMQBtdE3sAI4HTqLtAN0w9t3RIuiRbcALgNtp4pQZV/Is4N3dGOMdIIAnzXgsSZLWlQFoo2rie2niMcCJ3Vce291uYTmAPER7JhbATd39mbRdmpfMuKLnAN8H7OThHSCAJ894LEmS1pUBaOP6W+BTLAcgaNff3Anc1W2Pd4Au6e5f3d0/nyaOoInTaWIWnxT9/WOPJztABqD11sSbaeJimoihS5GkeVBdAIqIl0bE1yLi6oh4+9D1PEwTr6CJc2jieODHgOcCr6I922rkzu4GD18DNApAozPFngv8CvARRqFomjfPdk3RccCOsa+OOkD/0z2uJwA18WyaOKznMQP4NdrPXDq517ElaU5VFYAiYhPw57RvJE8HTouIp/deSBOH08RC9/hUmvgQTTwauAA4D/jNsWc/H/hX4L+77btY7gAlywFoL+0lKuievw14R7f9Jpo4HbiaJp7cjbtyV6iJxW7cX+i+cm13P+oAJW04e8qKrzULTRxGE+fTxEU08fbeuyHtz+MK4I97Hbdd//UD3ePTeh4bmjiTJo7tfVxJWke1nQZ/MnB1Zl4DEBEfA14JfHWNr3tU99rX0HZnfgS4EjicJv4S+FPajswvAb8OvBX4CZp4F/B22stL7KLtsjwAvKWr6UHg2bRvuqNOy8E6QNcC3wSeCvwhcBHwaOAq2vVAz6ddRP0+mrgJeBlNvKr7N48BrmAhkyZ2Ai8DLgX2AMcBv9XV8lngDSx3gKCdBnsGTWwHfof22mC/CvwwcB9tGNsO3MNC3sva/B5wNnA1bVfrXuBP1viaq9MGxwto9303TfwZbRC9gYXc/4j/dvoxN9EG2dNof/7/ApxKE+cBW1nIr0/5um1wbH/fW4FkIe/vfvf30p5p+ELa/6Z+lvZn/DjaRfCSNBdqC0CPB64b276etV4+ookzgd8Fjui+so/25/qabjuAM7rHdwFL3eOvAO+i7aBc3D3/M8AXaUPRJ/n/AejVPLwDNFoDtB+4kTbMPK4b40baN8/XdmNtAf4IeFv3b2/qxtvc1Xg1TXyLNsiNTmvfD/xBV883gGZsH0e+Apzavd6juppOA0bTRDfQ/tzvp4n/og1xtwHfpg1Gd9K+4R7R/dsHunG30oap0Q3aRdifAz5GGybPo4lzu9e4baKuQ7WJNggm7c93FEbvpA2BT+xe//xu7C93/+Y2mvg27Zl613XP+R7g5u77R3a1bel+JnfR/sy3dM8dhdgcu0H7O3kmcGz3vK8CXwd+nFEnrg2yt3fP/w4PPyMwaH++27paHksb1L8JnABsoYlrgAXgIZq4jnad177utR47VsvfAb9/CD9LSdrwIjNXftaciIjXAT+dmW/qts8ATs7MsyaetxvY3W0+DfjaCi+9neUFwTWpcb9r3GdY3X4/KTN3rPCcwUTELSxP4z6SGn/HNe4z1LnfxR/Ls1JbB+h64Alj28cD35p8UmbuoZ3+WZWI2JuZu9ZeXllq3O8a9xnmY79X+wd9Hvb1UNW4z1Dnfte4zwdT1SJo4DLgqRHx5Ig4DPg54O8HrkmSJPWsqg5QZu6LiF8G/pF2fcYHMvPKgcuSJEk9qyoAAWTmxbSLjmdp1dNlc6bG/a5xn6Gu/a5pX0dq3Geoc79r3OcDqmoRtCRJEtS3BkiSJMkAtFYb+tIa6yAinhARn42IqyLiyog4e+ia+hQRmyLi3yPiU0PX0oeIODYiPhERTfc7f97QNa2X2o5lqPt4ru1YhrqO59VwCmwNuktrfB34KdpT7C8DTsvMtX6y9IYVETuBnZn5pYg4GrgceNU87/O4iHgr7ad2H5OZLx+6nvUWER8GPp+ZF3RnTh6ZmXcMXdes1XgsQ93Hc23HMtRzPK+WHaC1+b9La2TmA7SfUPzKgWtaV5l5Y2Z+qXt8F+2lNh4/bFX9iIjjaS8NccHQtfQhIo6hvSTG+wEy84E5/mNZ3bEM9R7PtR3LUN3xvCoGoLU50KU15v6Px0hEnEB7oc5Lh62kN+cD57J8/bV59xTgFuCD3VTBBRFx1NBFrZOqj2Wo7niu7ViGuo7nVTEArc2BrkZexZxiRGyjvV7ZOZl550rPL11EvBy4OTMvH7qWHm0GngO8NzNPAu6hvS7cPKr2WIa6judKj2Wo63heFQPQ2qzq0hrzJiK20P6xvDAzLxq6np6cArwiIr5BOz3yooj46LAlrbvrgeszc9QR+ATtH9B5VOWxDFUezzUey1DX8bwqBqC1qe7SGhERtHPIV2XmeUPX05fMfEdmHp+ZJ9D+nj+TmacPXNa6ysybgOsi4mndl36S9qr086i6YxnqPJ5rPJahuuN5Var7JOhZqvTSGqcAZwD/GRFXdF/7je4TtjV/zgIu7ELBNcAbB65nXVR6LIPHc22qOJ5Xy9PgJUlSdZwCkyRJ1TEASZKk6vwvXVuqv9hZ14cAAAAASUVORK5CYII='></td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row7_col8" class="data row7 col8" >9/10 0.02 2%</td>
</tr>
<tr>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row8_col0" class="data row8 col0" >fare</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row8_col1" class="data row8 col1" >8</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row8_col2" class="data row8 col2" >float64</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row8_col3" class="data row8 col3" >Fare paid for ticket</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row8_col4" class="data row8 col4" >0<br/> 0%</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row8_col5" class="data row8 col5" >248<br/> 28%</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row8_col6" class="data row8 col6" >[0.0, 7.9104, 14.4542, 31.0, 512.3292]<br/> mean: 32.20 std: 49.69<br/> cv: 1.54 skew: 4.78*<br/> log skew: 0.90</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row8_col7" class="data row8 col7" ><img src='data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAkAAAACQCAYAAADgO9QwAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADl0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uIDMuMC4zLCBodHRwOi8vbWF0cGxvdGxpYi5vcmcvnQurowAAGOpJREFUeJzt3X+wVOV9x/H318svRYOK2KFABINJRJIQixqNphhjomlXTIMp3vxwGjM0TWxjrJPitLHGTiaj+YG2OlE62skYt6DGpKwlQ0xQ87NErCAgEq9EK5BEBSUBRQS+/eN5Fs497L137949u+e4n9fMzu55znP2+V52n8v3Puc55zF3R0RERKSTHNLuAERERERaTQmQiIiIdBwlQCIiItJxlACJiIhIx1ECJCIiIh1HCZCIiIh0HCVAIiIi0nGUAImIiEjHUQIkIiIiHUcJkIiIiHQcJUAiIiLScZQAiYiISMdRAiQiIiIdRwmQiIiIdJxCJkBmdp6ZbTCzHjObX2P/SDNbHPevMLPJqf1vNLMdZnZlq2IWERGR/ChcAmRmXcDNwPnANOBiM5uWqnYp8KK7TwUWANel9i8Avp91rCIiIpJPw9odQANOBXrcfSOAmS0CZgOPJ+rMBq6Jr+8BbjIzc3c3swuBjcDOehozs+eBZ5oUu8jr2XHuPq7dQfRFfVmkbrnuy81SxARoAvBsYnsTcFpfddx9j5ltB8aa2SvAPwDnAvWe/nrG3WcOLWSR1z8zW9nuGAagvixShwL05aYoYgJkNcq8zjpfAha4+w6zWlXiwWbzgHlx85hGghQREZH8KmICtAmYlNieCGzpo84mMxsGjAG2EUaK5pjZ9cCRwD4z2+XuNyUPdveFwELonExYRESkkxQxAXoYOMHMpgCbgblAd6rOEuAS4BfAHGC5uztwVrWCmV0D7EgnP01VNgOm0+1rMmtDREREBq1wV4G5+x7gMmAZsB64y93Xmdm1ZnZBrHYbYc5PD3AFcNCl8i1yGvAYZXtPm9oXERGRGoo4AoS7LwWWpsquTrzeBVw0wHtck0lwvVVn0Z8N/LgF7YmIiEgdCjcCVDCj4vOZbY1CREREelEClK1qAnQ6ZSvkaJuIiMjrkRKgbFUToNHAO9oZiIiIiBygUYmslG0eMCtRcibwSHuCEZHBKpVKNwAzgKmxqKdGtVWVSuXy1kUlIs2iBChbw+PzVuBdwI1tjEVEBmfGocP2/mn1LqsTx+yakNy5efsoXtnT1YawRKQZlABlq5oAPQ0c3cY4RKQBE8bs2v/6c2f9ute+G38yhZ6to1sdkog0ieYAZWs4sA/YTpgHJCIiIjmgBChbw4HXgJdRAiQiIpIbSoCyNRzYA+xECZCIiEhuKAHK1jDCCNBO4LA2xyIiIiKREqBsVU+BaQRIREQkR5QAZWsYOgUmIiKSO0qAspWcBD2csg0foL6IiIi0gBKgbCVPgYHmAYmIiOSCEqBspRMgnQYTERHJASVA2VICJCIikkNKgLJVnQT9ctxWAiQiIpIDSoCypREgERGRHCpkAmRm55nZBjPrMbP5NfaPNLPFcf8KM5scy081s1XxsdrMPpRxqMk7QYMmQYuIiORC4RIgM+sCbgbOB6YBF5vZtFS1S4EX3X0qsAC4LpavBWa6+wzgPOBWMxuWYbjJO0GDRoBERERyoXAJEHAq0OPuG919N7AImJ2qMxv4Vnx9D3COmZm7v+zue2L5KMAzjjV5HyBQAiQiIpILRUyAJgDPJrY3xbKadWLCsx0YC2Bmp5nZOmAN8OlEQpQFzQESERHJoSImQFajLD2S02cdd1/h7icBpwBXmdmogxowm2dmK81sJXDMEOLsQjdCFBERyZ0iJkCbgEmJ7YnAlr7qxDk+Y4BtyQruvp6QmExPN+DuC919prvPBF5oMM7qshcaARIREcmZIiZADwMnmNkUMxsBzAWWpOosAS6Jr+cAy93d4zHDAMzsOOAtwNMZxVmdXL2Hbt9NuBpMCZCIiEgOZHkFVCbcfY+ZXQYsI5xiut3d15nZtcBKd18C3AbcYWY9hJGfufHwM4H5ZvYasA/4jLs3OsIzkOQIEISJ0EqARHKsVCrdAFCpVC4v0nuLyOAVLgECcPelwNJU2dWJ17uAi2ocdwdwR+YBBukEaCdKgETybkZB31tEBqmIp8CKolYCpEnQIiIiOaAEKDsH5gAFGgESERHJCSVA2dEcIBERkZxSApQdzQESERHJKSVA2al1CkxzgERERHJACVB2NAIkIiKSU0qAsqM5QCIiIjmlBCg7GgESERHJKSVA2amdAJWt1kKtIiIi0kJKgLJTaxL0IcCI9oQjIiIiVUqAslNrDhDoNJiIiEjbKQHKTjUBSo4AgRIgERGRtlMClJ1hHEh+AP4Qn9/QhlhEREQkQQlQdoZz4PQXwLb4fFQbYhEREZEEJUDZSSdAW+Pz0W2IRURERBKUAGWnrxEgJUAiIiJtpgQoO30lQGPbEIuIiIgkDBu4ijQoPQn698BeNAIk0slGl0qll4FD+9jvQPVmqR+uVCr3ApRKpXcAPwW64rFXA08Ai4E5iXoXxbJ9wPuAF4GHgGuBr1XLK5XKg/E9HwLOqlQqaxr5YRLtzalUKveWSqXxwCLgDmBhMrbEMQe1WyqVrgS+Cny+Uqnc0EgsMrBSqXQOsIz4HWhzOG1XyBEgMzvPzDaYWY+Zza+xf6SZLY77V5jZ5Fh+rpk9YmZr4vN7Mwyz9whQtzvhl5ESIJHOdSJ9Jz9wIPkBuDPx+tvA4Yljv0RIMixVr1rWBdwTjxtDSH6S5ST2lRv4OdLtVWP4InAmcEuN2JI/S7rd6+Pz14cQiwzsLnp/Bzpa4RIgM+sCbgbOB6YBF5vZtFS1S4EX3X0qsAC4Lpa/AJTc/W3AJYTOm5URwO5U2TaUAIl0qtEM7j5go0ql0l/EEZPpqX0GjEzVuyhRBuF0+/RE/f3lpVLpk4l900ul0tsGERewf/QnGcMngb8i/L/SlYwtcUzyZ5leKpXeFkd/qvEdUiqVLh9sLDKwOPpT/f9nbKlUmtXGcHKhiKfATgV63H0jgJktAmYDjyfqzAauia/vAW4yM3P3RxN11gGjzGyku7+aQZzDgR2psq0oARLJs6nA4aVS6UFgxvM7RzBudPrvmOD5nSMAZsS69XhnA/HcCfTUWW8w6wwuTG2XgcEmQek/IG8lnOZPu5MDI1ffrtHuSamyrwM6DdZ8d6W27wGOaUcgeVG4ESBgAvBsYntTLKtZx933ANs5ePLxh4FHM0p+4OBJ0KARIJGWMrN5ZrbSzFbS/l/2XQNXOcgoDh796aveyAFr9R1LPW2kpdsb1kcMo/ppZzoHJ25F/H+pCNL/93T8BTlFHAGq9VeOD6aOmZ1EOC32/poNmM0D5sXNRn9pHjgFVrbqe40Fjmvw/URkkNx9IXG0IyZBA+kBqFQqs0ql0oPjRu/+074qjhu9m+27hq+qVCqz6omlVCrtYPBL4eyKMQ2UoOyi92mxgeyldxK0dpBxAbyaam9PfN90DLtS7UxPbZ9E79/Z+xqIRQaW/gN8a18VO0URM+1NwKTE9kRgS191zGwYYcLdtrg9Efgu8Al3f6pWA+6+0N1nuvtMwryhRozg4BGgnWgtMJFOtb6BYz4KfKzOeh8fxPvOS213D+LYqnR7f83Bf4xCiK0q/bN0A19Ilf19A7HIwD6S2p7TlihypIgJ0MPACWY2xcxGAHOBJak6SwiTnCF8yMvd3c3sSOC/gavc/WcZxzmcgydB7wRGUbbhNeqLyOvbTg4silyPXZVK5d5KpbKag0donDACk6x3d6IMwl/4axP195dXKpXbE/vWNnIZfKq9XfE9/4MwgrM3UX5v4pjkz7K2UqmsqVQqX0vEt0+XwWejUqn8iAP3o9uqy+ALmADFOT2XEe5lsB64y93Xmdm1ZnZBrHYbMNbMeoArgOql8pcRJjl+0cxWxcexGYVa6yqw6i8/rQcm0pnWA6/0sz+ZqKRHTnYkjv1nwgiMp+pVy/YS/vj7GGEO5JWpchL7Ghn9SbdXjeFfCPcr+nSN2JI/S7rd6iiQRn+y9RF6fwc6mrnXGrGUKjNbGU+F1a9shxC+ZBXgvsSeU4BPASfS7U80LUiRHGior7RQPfFVr+iqzgGaOnbn/jlAnzvr173q3viTKfRsHf3QIOYA7X/vQQUu0mJ578vNUrgRoIKoXvLZ1wiQrgQTERFpIyVA2agmQLUmQYMuPxQREWkrJUDZ6GsE6OX4rBEgERGRNlIClI2BRoCUAImIiLSREqBsHBaf0yNArxCujFACJCIi0kZFvBN0EfQ1AuSES1nPpWxhOY9uT6/JIyIiIhnTCFA2+poDBLAK+BPgiNaFIyIiIklKgLLRXwJ0P2ENnrNbF46IiIgkKQHKRl+nwAB+B6wGZhHuFi0iIiItpgQoG9VJ0LUSIAijQKOBM1oTjoiIiCQpAcpGf6fAAHqAjcD7KFtXa0ISERGRKiVA2RgoAQL4ATAOuDD7cERERCRJCVA2+psDVLUKeBV4T/bhiIiISJISoGwcRrjnz55+6jjwPPCmlkQkIiIi+ykBysah9D/6U/U8cHzGsYiIiEiKEqBsHEr/83+qQgJUNn0OIvmwKj6K9t4iMkhaCiMb9SZALwAjgfHA5kwjEpEBVSqVy4v43iIyeIUceTCz88xsg5n1mNn8GvtHmtniuH+FmU2O5WPN7AEz22FmN2UY4mBOgYHmAYmIiLRU4RIgM+sCbgbOB6YBF5vZtFS1S4EX3X0qsAC4LpbvAr4IXJlxmIcxuARI84BERERaqHAJEHAq0OPuG919N7AImJ2qMxv4Vnx9D3COmZm773T3nxISoSzVewpsG7APjQCJiIi0VBEToAnAs4ntTbGsZh133wNsB8a2JLqg3lNge4H/QyNAIiIiLVXESdBWo8wbqNN3A2bzgHlx85h6j0uodwQI4Ck0AiQiItJSRRwB2gRMSmxPBLb0VcfMhgFjCKeb6uLuC919prvPJFypNViHUX8CtBGNAImIiLRUEROgh4ETzGyKmY0A5gJLUnWWAJfE13OA5e5e9whQE9R7CgzCCNA4ynZEhvGIiIhIQuFOgbn7HjO7DFgGdAG3u/s6M7sWWOnuS4DbgDvMrIcw8jO3eryZPQ28ARhhZhcC73f3x5sc5mASoI3x+XhgdZPjEBERkRoKlwABuPtSYGmq7OrE613ARX0cOznT4ILBzgGCMA9ICZCIiEgLFPEUWBEMJgFKjgCJiIhICygBarayDQOGU+8psG5/iXCaTleCiYiItIgSoOY7ND7XOwIEuhJMRESkpZQANV81Aap3EjToXkAiIiItpQSo+RodATounj4TERGRjCkBar7D4vNgEqCnCFfkTRqoooiIiAydEqDmOzY+7xjEMboSTEREpIWUADVfdRTnxbpql20eYYV7gEuzCEhERER6UwLUfINLgA7U3Qa8pfnhiIiISJoSoOabREhmBjMHCGA98FbK1tX8kERERCRJVx013xuBZxs4bj3wbuBkwoKvItJmm7ePorqK8o0/mXLQPhEpLiVAzTcJeKaB456Iz++jmgCV7d+AM4HFwDa6fWEzAhSRuqx6ZU8XwFSAnq2je2rVaWlEItI0SoCabxLw0waO+wOwCZhN2a4HvgZcFvcdDnz9oCPKZoRfzk631/rlLCINqlQql7c7BhHJjuYANVPZDgeOorFTYAA/Bk4DHgMuBx4AvkVIcs5LtfVW4EngV8AaynZyg22KiIh0HCVAzVW9AqzRBOgh4EvANOCbwCLg58BK4M8oW7hPUNneAfwSGAeUgVeAeynb2IYjFxER6SBKgJprqAkQhATorRw4/QVwN7AXuJmyXUgYGdoDfJWQNH0TGA/8ezwtJiIiIv1QAtRcQ0+Aut3p9g10+75E6UvAEsJpsO/G7a8Cz8X9zwD/BHwIuKThtkVERDqEJkE31yTAgc0Nv0O4M3QtPyRcKn8UYemMl1P7f0+YD7SQsv2Kbv95wzGIiIi8zhVyBMjMzjOzDWbWY2bza+wfaWaL4/4VZjY5se+qWL7BzD7Q5NDeDmyh2wd7E8R6bQbWcnDyAyHxupVwV+n7KNuJvfaWbSRlO5uynUvZjs4oPhERkUIo3AiQmXUBNwPnEi4bf9jMlrj744lqlwIvuvtUM5sLXAf8pZlNA+YCJwF/DPzQzN7s7nuHHFjZpgEXxrbaZQdwI/B3wDLKdgbdvomynQ7cBpy4v17ZbgG+Qbf/BoCyjQc+AowC7qbbN1K2KwjrlE0HfgYsoNufIA/KdigwC1hNt29pczQiIlIw5u4D18oRMzsduMbdPxC3rwJw968k6iyLdX5hZsOA3xKumJqfrJus1097K919Zr9BheUrFhHm6Eyh21/o51RWKzxMmBwNsAY4g7A8x3cISdIZhMRmL7AcMOAceo8IbgPeQEiSfwscSUiOlsRjNsX3foruOhPIso0BSsAcwsr3q4AeYDRwCuEz+i3wPeB7dPtmyjYy1h0N7IsxXAucDhwWy74LXEO3r63vn0cOEm7hcDrwZsK/6/8Cv6Tb/1DvW9TVV9oo7/GJ5EWn9JXCjQABE+g9yXgT4d45Neu4+x4z2w6MjeX/kzp2wpCiKdvnCROQjwa+TLe/MKT3a45TgAWEu0ofT0golgOvxv1PABXgbMLVYyOBrxDWL9sNzADeRJhX9GPgN/E9PgN8Frgg0dZuyvYU4VL8XYSr04yQTFnicTQwBRhOmMS9mZB0fRx4DXg0Hjs9xn0TZdtBSHzSV7btpfofdIjzXODDlG0zsCXu35d49KW/K+YGupqu0WPz2OYUwueTrrePsvUALwA30O13DxCfiEhhFHEE6CLgA+7+qbj9ceBUd//bRJ11sc6muP0UYcTjWuAX7v7tWH4bsNTdv5NqYx5QHcF5C7ChgVCPIfzH0W6Ko7e8xAH5iaVZcRzn7uOa8D6ZMLPnqW+Zmrx8LlWKp3+Kp3+NxJPrvtwsRRwB2sSBy80BJhL+6q9VZ1M8BTaGcEqnnmNx94XAkNbdyssQouLIZxyQn1jyEkfW6v2Fnrd/D8XTP8XTv7zFkydFvArsYeAEM5tiZiMIk5qXpOos4cD9cOYAyz0MdS0B5sarxKYAJxBOo4iIiEgHKdwIUJzTcxmwDOgCbnf3dWZ2LbDS3ZcQrni6w8x6CCM/c+Ox68zsLuBxwnyTzzblCjAREREplMIlQADuvhRYmiq7OvF6F3BRH8d+GfhypgEGQzqF1kSKo7e8xAH5iSUvceRF3v49FE//FE//8hZPbhRuErSIiIjIUBVxDpCIiIjIkCgBarKBlunIoL3bzew5M1ubKDvazO43syfj81Gx3MzsX2Nsj5nZyU2MY5KZPWBm681snZl9rh2xmNkoM/ulma2OcXwplk+Jy6I8GZdJGRHL+1w2pUnxdJnZo2Z2X7viMLOnzWyNma0ys5WxrOXfkbxrdd+Nbeai/ybazkU/TsSTq/6ciKvt/ToRi/p3o9xdjyY9CJOynyLcfHAEsBqYlnGb7wFOBtYmyq4H5sfX84Hr4usPAt8n3PDuXcCKJsYxHjg5vj6CsDDrtFbHEt/v8Ph6OLAivv9dwNxYfgvwN/H1Z4Bb4uu5wOImfz5XAGXgvrjd8jiAp4FjUmUt/47k+dGOvhvbzUX/TbSdi36ciCdX/TkRV9v7dSIW9e9G/+3aHcDr6UFYSmBZYvsq4KoWtDs59Qt0AzA+vh4PbIivbwUurlUvg5j+i3CH5rbFwoElHU4j3AhsWPpzIlxNeHp8PSzWsya1PxH4EfBe4L74S6cdcdT6Bdn270ieHu3qu7Gt3PXfRBtt78eJ925rf07EkYt+nYhH/bvBh06BNVetZTqGttRGY/7IPSxyGp+PjeUtiS8O876T8Nday2OJw9OrgOeA+wl/2b/k7ntqtNVr2RSgumxKM9wAfIEDy3GMbVMcDvzAzB4x279GXVu/IzmUp587F59Nu/txIo689OeqvPTrKvXvBhXyMvgcq7XmUp4us8s8PjM7nLDo6uXu/nuzPpehyiwWD/d2mmFmRxIWSj2xn7YyicPM/hx4zt0fMbNZdbSV5WfzbnffYmbHAveb2RP91M37dzgrRfi5WxZjHvrx/jfLQX+uylm/rlL/bpBGgJqrrqU2WuB3ZjYeID4/F8szjc/MhhN+ad7p7ve2MxYAd38JeJBwrvtIC8uipNvaH4f1XjZlqN4NXGBmTwOLCMPlN7QhDtx9S3x+jvAfyKm08XPJqTz93G39bPLWj6va3J+rctOvq9S/G6cEqLnqWaajFZJLgVxCOI9fLf9EvBLgXcD26jDpUFn4E/E2YL27f6NdsZjZuPiXImZ2KGFl+fXAA4RlUWrFUWvZlCFx96vcfaK7TyZ8D5a7+0dbHYeZjTazI6qvgfcDa2nDdyTn8tJ3oY2fTV76cSKeXPTnqrz06yr17yFq9ySk19uDMMv+V4Tz1P/Ygvb+E/gN8Bohu7+UcI75R8CT8fnoWNeAm2Nsa4CZTYzjTMJQ6mPAqvj4YKtjAd4OPBrjWAtcHcuPJ6z71gPcDYyM5aPidk/cf3wGn9EsDlwt0tI4Ynur42Nd9TvZju9I3h+t7ruxzVz030Q8uejHiXhy158TsbWtXydiUP8ewkN3ghYREZGOo1NgIiIi0nGUAImIiEjH+X8zfO3zfH/GzAAAAABJRU5ErkJggg=='></td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row8_col8" class="data row8 col8" >4/10 0.03 4%</td>
</tr>
<tr>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row9_col0" class="data row9 col0" >who</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row9_col1" class="data row9 col1" >9</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row9_col2" class="data row9 col2" >category</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row9_col3" class="data row9 col3" >Whether the passenger is man, woman, or child</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row9_col4" class="data row9 col4" >0<br/> 0%</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row9_col5" class="data row9 col5" >3<br/> 0%</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row9_col6" class="data row9 col6" >man 60%<br/> woman 30%<br/> child 9%</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row9_col7" class="data row9 col7" ><img src='data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAkAAAACQCAYAAADgO9QwAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADl0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uIDMuMC4zLCBodHRwOi8vbWF0cGxvdGxpYi5vcmcvnQurowAADVtJREFUeJzt3X+sX3V9x/HnS8rPLKz80kFbpM6GwZaBpOtgJrqhkR8iZQtMyKYdw3UOphA3Jy5ILco2Mh3TzWm6saV1zB/DLXSGSTpEjX+AFEUEKmvHIr0rylgLTuuUH+/98T1tvlwuWOn93nO/9/N8JDff8/mczzl5n9yT3FfO5/O9J1WFJElSS17QdwGSJEkzzQAkSZKaYwCSJEnNMQBJkqTmGIAkSVJzDECSJKk5BiBJktQcA5AkSWqOAUiSJDXHACRJkppjAJIkSc0xAEmSpOYYgCRJUnMMQGMsyfwkNyT5epJNSU5JcmiSDUk2d5+HPMuxK7oxm5Os6Pr2T/KZJPckuXho7JokL5up65IkadQMQOPtA8BnquqngBOATcDlwC1VtQS4pWs/TZJDgVXAzwPLgFVdUDoNuBP4WWBlN/YE4AVV9ZXRX44kSTPDADSmkhwMvAK4DqCqflBVjwLLgbXdsLXAOVMcfhqwoaq2V9UOYANwOvA4cCAwb2jse4ArR3IRkiT1JFXVdw2zWpL/Br7Rdx1TOBA4BvgecBDwXWArg6c3dw2NO3FSG+BFDMLvQ137SOAp4FvA4u7c3wSe7M79EJKkVry4qo7ou4hRm/fDhzTvG1W1tO8iJkuyFLgNOLWqbk/yAeDbwEuG602yY3L9Sd4O7F9V7+3a7wJ2VtX7h8bsC9wMnA1cBRwNrKuq9SO+NElSj5Js7LuGmeAU2PiaACaq6vaufQNwEvCtJEcCdJ8PP8uxi4baC4Ftk8ZczGAK7RTgB8DrgSumrXpJknpkABpTVfVNYGuSY7uuVwH3AeuBFV3fCuDGKQ6/GXhNkkO6xc+v6foA6PrOAtYxmAJ7CijggBFciiRJM84psPH2FuD6JPsBDwAXMgi1n0xyEfAgcB7snjJ7c1W9qaq2J3kPcEd3nquqavvQea8E3ltVleRm4BLga8BHZuSqJEkaMRdB/xBJNs62NUCrs9pf2h5aVavSdw2SNE5m49+9UXAKTJIkNccAJEmSmmMAkiRJzTEASZKk5hiAJElScwxAkiSpOQYgSZLUHAOQJElqjgFIkiQ1xwAkSZKaYwCSJEnNMQBJkqTmGIAkSVJzDECSJKk5BiBJktQcA5AkSWqOAUiSJDXHACRJkppjAJIkSc0xAEmSpOYYgCRJUnMMQJIkqTlzIgAl2SfJV5J8umsvTnJ7ks1JPpFkv65//669pdt/TJ91S5KkfsyJAARcCmwaal8DXFtVS4AdwEVd/0XAjqp6KXBtN06SJDVm7ANQkoXAa4G/6doBTgVu6IasBc7ptpd3bbr9r+rGS5Kkhox9AAL+HPgD4KmufRjwaFU90bUngAXd9gJgK0C3/7FuvCRJashYB6AkZwEPV9Wdw91TDK092Dd83pVJNibZCBy+95VKkqTZZF7fBeyllwNnJzkTOAA4mMEToflJ5nVPeRYC27rxE8AiYCLJPODHge2TT1pVa4A1AF0IkiRJc8hYPwGqqndW1cKqOgY4H/hsVf0acCtwbjdsBXBjt72+a9Pt/2xVPeMJkCRJmtvGOgA9h3cAb0uyhcEan+u6/uuAw7r+twGX91SfJEnq0bhPge1WVZ8DPtdtPwAsm2LM/wHnzWhhkiRp1pmrT4AkSZKelQFIkiQ1xwAkSZKaYwCSJEnNMQBJkqTmGIAkSVJzDECSJKk5BiBJktQcA5AkSWqOAUiSJDXHACRJkppjAJIkSc0xAEkCIMkBSb6U5KtJ7k2yuutfnOT2JJuTfCLJfs9y/DuTbElyf5LTur4jknwxyT1Jzhkae2OSo2bmyiTpmQxAknb5PnBqVZ0AnAicnuRk4Brg2qpaAuwALpp8YJLjgfOBnwZOB/4qyT7ABcBa4BTg7d3Y1wFfrqpto78kSZqaAUgSADXwna65b/dTwKnADV3/WuCcKQ5fDny8qr5fVf8JbAGWAY8DBwL7A08lmQdcBvzpyC5EkvaAAUjSbkn2SXIX8DCwAfgP4NGqeqIbMgEsmOLQBcDWofaucf8AnAZ8Bng3cDGwrqp2juQCJGkPGYAk7VZVT1bVicBCBk9wjptq2BR9mfp09VhVvbaqlgJfBs4CPpXkr5PckOSUaStekn4EBiBJz1BVjwKfA04G5ndTVzAIRlOt3ZkAFg21pxp3JXA1g3VBdwK/CfzR9FUtSXvOACQJ2P2Nrfnd9oHAq4FNwK3Aud2wFcCNUxy+Hjg/yf5JFgNLgC8NnXsJcFRVfR44CHiKwZOkA0Z0OZL0nAxAknY5Erg1yd3AHcCGqvo08A7gbUm2AIcB1wEkOTvJVQBVdS/wSeA+But9LqmqJ4fOfTVwRbf9MeA3gNuA9436oiRpKqmaajpfuyTZ2K1fmDVWZ7W/tD20qlZNtTZFk3hP7RnvJ7VgNv7dGwWfAEmSpOYYgCRJUnMMQJIkqTkGIEmS1BwDkCRJao4BSJIkNccAJEmSmmMAkiRJzRnrAJRkUZJbk2xKcm+SS7v+Q5NsSLK5+zyk60+SDybZkuTuJCf1ewWSJKkPYx2AgCeA36uq4xi8tPGSJMcDlwO3VNUS4JauDXAGg3cULQFWAh+e+ZIlSVLfxjoAVdVDVfXlbvt/Gby4cQGwHFjbDVsLnNNtLwfW1cBtDN5yfeQMly1Jkno21gFoWJJjgJcBtwMvqqqHYBCSgBd2wxYAW4cOm+j6JElSQ+b1XcB0SPJjwKeAy6rq28mzvq9wqh3PeAlkkpUMpsgADp+WIiVJ0qwx9k+AkuzLIPxcX1X/1HV/a9fUVvf5cNc/ASwaOnwhsG3yOatqTVUt7d6G+8jIipckSb0Y6wCUwaOe64BNVfVnQ7vWAyu67RXAjUP9b+y+DXYy8NiuqTJJktSOcZ8CeznwBuBrSe7q+v4Q+BPgk0kuAh4Ezuv23QScCWwBdgIXzmy5kiRpNhjrAFRVX2TqdT0Ar5pifAGXjLQoSZI06431FJgkSdLzYQCSJEnNMQBJkqTmGIAkSVJzDECSJKk5BiBJktQcA5AkSWqOAUiSJDXHACRJkppjAJIkSc0xAEmSRiLJpUnuSXJvksum2J8kH0yyJcndSU7q+o9NcmeSryY5peubl+Tfkhw009ehuckAJEmadkl+BvgtYBlwAnBWkiWThp0BLOl+VgIf7vp/G7gcOBf4/a7vd4CPVtXOEZeuRhiAJEmjcBxwW1XtrKongM8DvzxpzHJgXQ3cBsxPciTwOHAgcBDweJL5wOuAdTNXvua6sX4bvCRp1roHuDrJYcD3gDOBjZPGLAC2DrUnur4PMQg7+zN4GnQlcHVV1aiLVjsMQJKkaVdVm5JcA2wAvgN8FXhi0rBMfWg9CPwiQJKXAkcBX0/yUWA/4F1V9e+jql1tcApMkjQSVXVdVZ1UVa8AtgObJw2ZABYNtRcC2yaNuRp4F/BW4HpgVfcj7RUDkCRpJJK8sPs8GvgV4GOThqwH3th9G+xk4LGqemjo+FcC/1VVmxmsB3oKeLLblvaKU2CSpFH5VLcG6HHgkqrakeTNAFX1EeAmBmuDtgA7gQt3HZgkwBXAr3Zdaxg8AZrH4Bth0l6Ja8qeW5KNVbW07zqGrc5qf2l7aFWtmmqNgSbxntoz3k97zntqz8zGe2o2/t0bBafAJElScwxAkiSpOQYgSZLUHAOQJElqjgFIkiQ1xwAkSZKaYwCSJEnNMQBJkqTmGIAkSVJzDECSJKk5BiBJktSc5gJQktOT3J9kS5LL+65HkiTNvKYCUJJ9gA8BZwDHAxckOb7fqiRJ0kxrKgABy4AtVfVAVf0A+DiwvOeaJEnSDGstAC0Atg61J7o+SZLUkFRV3zXMmCTnAadV1Zu69huAZVX1lknjVgIru+axwP0zWuh4Ohx4pO8iNKd4T2m6eU/tmRdX1RF9FzFq8/ouYIZNAIuG2guBbZMHVdUaYM1MFTUXJNlYVUv7rkNzh/eUppv3lIa1NgV2B7AkyeIk+wHnA+t7rkmSJM2wpp4AVdUTSX4XuBnYB/jbqrq357IkSdIMayoAAVTVTcBNfdcxBzllqOnmPaXp5j2l3ZpaBC1JkgTtrQGSJEkyAEmSpPYYgCRJUnOaWwSt6ZVkAfBihu6lqvpCfxVp3CX5BeAYnn5PreutII2dJIc+1/6q2j5TtWj2MgDpeUtyDfB64D7gya67AAOQnpckHwV+EriLp99TBiD9KO5kcN8EOBrY0W3PBx4EFvdXmmYLA5D2xjnAsVX1/b4L0ZyxFDi+/Hqq9kJVLQZI8hFgfffvT0hyBvDqPmvT7OEaIO2NB4B9+y5Cc8o9wE/0XYTmjJ/bFX4AqupfgVf2WI9mEZ8AaW/sBO5Kcguw+ylQVb21v5I05g4H7kvyJZ5+T53dX0kaY48kuQL4ewZTYr8O/E+/JWm2MABpb6zHd6lper277wI0p1wArAL+uWt/oeuT/E/QkiSpPT4B0vOWZAnwx8DxwAG7+qvqJb0VpbGW5GTgL4DjgP0YvLT4u1V1cK+Faawk+RcGU15TckpVYADS3vk7Bo+XrwV+CbiQwVdNpefrL4HzgX9k8I2wNwJLeq1I4+h9fReg2e//AaSGXZAihTphAAAAAElFTkSuQmCC'></td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row9_col8" class="data row9 col8" >1/10 0.44 49%</td>
</tr>
<tr>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row10_col0" class="data row10 col0" >deck</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row10_col1" class="data row10 col1" >10</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row10_col2" class="data row10 col2" >category</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row10_col3" class="data row10 col3" ></td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row10_col4" class="data row10 col4" >688<br/> 77%</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row10_col5" class="data row10 col5" >8<br/> 1%</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row10_col6" class="data row10 col6" >nan 77%<br/> C 7%<br/> B 5%<br/> D 4%<br/> E 4%<br/> A 2%<br/> F 1%<br/> G 0%</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row10_col7" class="data row10 col7" ><img src='data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAkAAAACQCAYAAADgO9QwAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADl0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uIDMuMC4zLCBodHRwOi8vbWF0cGxvdGxpYi5vcmcvnQurowAAEpNJREFUeJzt3X20ZFV55/HvT5oGQREUNYQmaSPESeKKSgji6olROwZEY5Mo2kaROBjyggSisxxwRqF9IcZMFB0NCUqykDgEgxA7hvgS0SRmDQwtMig2hIYgXEHAlwAjThR95o+zL10p6nZD971Vt+p8P2vVuufsvc/tZ3c19z7s/Zw6qSokSZL65GGTDkCSJGncTIAkSVLvmABJkqTeMQGSJEm9YwIkSZJ6xwRIkiT1jgmQJEnqHRMgSZLUOyZAkiSpd0yAJElS75gASZKk3jEBkiRJvWMCJEmSescEaAkleVKSqwZedyc5OckFA203JblqgeuPSHJdki1JThlo/1CSq5OcMdD2xiTrxjEvSZKm3YpJBzDLquo64KkASXYBvgpcXFVnzo9J8ofAXcPXtvHvA54LzAFXJNlIe8+q6qeT/GOSRwF7AIdW1VuWeEqSJM0EV4DGZy1wQ1V9Zb4hSYCXAOePGH8osKWqbqyq7wJ/AawDvgc8PMnDgJXA94E3A29a4vglSZoZqapJx7CsJbkT+Mp2B27fauDbwJ0DbY8ADgA2jxi/D7DXwJ/96Db+5nbNI4FvAHcDj1ukGCVJ+tGqeuykg1hqboFt31eq6pCd+QZJVgK30m1T3T7QfhbdKs8fjrjmaODwqnp1Oz+mXX/i0Li/ptsmexXwFOBTVfX+nYlXktRfSTZNOoZxcAtsPJ4HXDmU/KwAfgW4YIFr5uhWeuatokui7teKnjcBewJPrqqXAMck2WMRY5ckaeaYAI3Hy3hgnc8vANdW1dwC11wBHJTkCW0FaT2wcb4zya7AScAf0BVBz+9lztcGSZKkBZgALbG2GvNc4KKhrvUMJUVJfjjJJQBVdR/wGuATdDVCH66qawaGnwCcW1X3Ald3l+eLwD9V1b8uyWQkSZoRFkFvR5JNO1IDtCEbxvoXe1qdlnH+eZKk2bSjv/emjStAkiSpd0yAJElS75gASZKk3jEBkiRJvWMCJEmSescESJIk9Y4JkCRJ6h0TIEmS1DsmQJIkqXemPgFKsneSC5Ncm2RzkmckeXSSTyW5vn3dp41Nkvck2ZLk6iQHTzp+SZI0flOfAAHvBj5eVf8BeArdc7NOAT5dVQcBn27n0D2V/aD2Oh44a/zhSpKkSZvqBCjJXsAzgXMAquq77UGg64Bz27BzgaPa8Trgg9W5DNg7yX5jDluSJE3YVCdAwI8BdwJ/luQLST6QZE/g8VV1G0D7+rg2fn/gloHr51qbJEnqkWlPgFYABwNnVdXTgG+zdbtrlFFPTH/AU9uTHJ9kU5JNwL6LEqkkSVo2pj0BmgPmqurydn4hXUJ0+/zWVvt6x8D4AwauXwXcOvxNq+rsqjqkqg4Bvr5UwUuSpMmY6gSoqr4G3JLkSa1pLfBlYCNwbGs7FvhoO94IvLLdDXYYcNf8VpkkSeqPFZMOYBGcCHwoyUrgRuBVdIndh5McB9wMHN3GXgIcCWwB7m1jJUlSz0x9AlRVVwGHjOhaO2JsAScseVCSJGlZm+otMEmSpB1hAiRJknrHBEiSJPWOCZAkSeodEyBJktQ7JkCSJKl3TIAkSVLvmABJkqTeMQGSJEm9YwIkSZJ6xwRIkiT1jgmQJEnqHRMgSZLUOyZAkiSpd0yAJElS75gASZKk3jEBkiRJvWMCJEmSescESJIk9Y4JkCRJ6h0TIEmS1DszkQAl2SXJF5J8rJ0/IcnlSa5PckGSla19t3a+pfWvnmTckiRpMmYiAQJOAjYPnP8+8K6qOgj4FnBcaz8O+FZVHQi8q42TJEk9M/UJUJJVwPOBD7TzAM8BLmxDzgWOasfr2jmtf20bL0mSemTqEyDgTOD1wA/a+WOAf62q+9r5HLB/O94fuAWg9d/VxkuSpB6Z6gQoyQuAO6rq84PNI4bWg+gb/L7HJ9mUZBOw785HKkmSlpMVkw5gJ60BXpjkSGB3YC+6FaG9k6xoqzyrgFvb+DngAGAuyQrgUcA3h79pVZ0NnA3QkiBJkjRDpnoFqKpOrapVVbUaWA9cWlUvBz4DvLgNOxb4aDve2M5p/ZdW1QNWgCRJ0myb6gRoG/4L8NokW+hqfM5p7ecAj2ntrwVOmVB8kiRpgqZ9C+x+VfVZ4LPt+Ebg0BFj/h9w9FgDkyRJy86srgBJkiQtyARIkiT1jgmQJEnqHRMgSZLUOyZAkiSpd0yAJElS75gASZKk3jEBkiRJvWMCJEmSescESJIk9Y4JkCRJ6h0TIEmS1DsmQJIkqXdMgCRJUu+YAEmSpN4xAZIkSb1jAiRJknrHBEiSJPWOCZAkSeodEyBJktQ7JkCSJKl3pjoBSnJAks8k2ZzkmiQntfZHJ/lUkuvb131ae5K8J8mWJFcnOXiyM5AkSZMw1QkQcB/wuqr6CeAw4IQkPwmcAny6qg4CPt3OAZ4HHNRexwNnjT9kSZI0aVOdAFXVbVV1ZTu+B9gM7A+sA85tw84FjmrH64APVucyYO8k+405bEmSNGFTnQANSrIaeBpwOfD4qroNuiQJeFwbtj9wy8Blc61NkiT1yIpJB7AYkjwC+AhwclXdnWTBoSPaasT3O55uiwxg30UJUpIkLRtTvwKUZFe65OdDVXVRa759fmurfb2jtc8BBwxcvgq4dfh7VtXZVXVIVR0CfH3JgpckSRMx1QlQuqWec4DNVfXOga6NwLHt+FjgowPtr2x3gx0G3DW/VSZJkvpj2rfA1gDHAF9MclVrewPwduDDSY4DbgaObn2XAEcCW4B7gVeNN1xJkrQcTHUCVFWfY3RdD8DaEeMLOGFJg5IkScveVG+BSZIk7QgTIEmS1DsmQJIkqXdMgCRJUu+YAEmSpN4xAZIkSb1jAiRJknrHBEiSJPWOCZB2WJInJblq4HV3kpOHxiTJe5JsSXJ1koMHrv18kv+T5BmtbUWSv0uyxyTmI0nqj6n+JGhNVlVdBzwVIMkuwFeBi4eGPQ84qL2eDpzVvv4GcApwE92jS14E/BZwXlXdO4bwJUk95gqQFsta4Iaq+spQ+zrgg9W5DNg7yX7A94CHA3sA30uyN/BLwAfHGfS2JLkpyRfb6tamEf2ubknSlHIFSItlPXD+iPb9gVsGzuda2/vokp3d6FaD3gS8rT2vbTl5dlV9fYE+V7ckaUq5AqSdlmQl8ELgL0d1j2irqrq5qp5VVc8A7gV+GLg2yXlJLkjy40sY8mKZ2tWteUl2SfKFJB8b0bdbey+2JLk8yerWvqateF2R5MDWtneSTyRZ6OHEEzHr85O040yAtBieB1xZVbeP6JsDDhg4XwXcOjTmbcAbgd8BPgSc1l6TVsAn23bW8SP6t7W69Vrgj4EzWL6rWwAnAZsX6DsO+FZVHQi8C/j91v46ulWtN9CtbEH3/p2xDOc46/OTtINMgLQYXsbo7S+AjcArW73MYcBdVXXbfGeSnwe+WlXX062Y/AD4fjuetDVVdTBdgndCkmcO9U/16laSVcDzgQ8sMGQdcG47vhBY21ZAhle4ngjsX1V/v8QhPySzPj9JO8cESDulFfU+F7hooO03k/xmO70EuBHYArwf+O2BcQH+G/CW1nQ2Xc3MR4D/vuTBb0dV3dq+3kF3d9uhQ0OmeXUL4Ezg9XRJ5yj3r3BV1X3AXcBjgN+je69OBt7L1jkuNzM7vyQHJPlMks1Jrkly0ogxU1ukn+RPk9yR5EsL9E/t3LR8xBXdbUuyqaoOeajXbciGsf7FnlanjbU2Ydbnl2RP4GFVdU87/hTw5qr6+MCY5wOvAY6kK35+T1UdOtD/88C6qnptkncBfwv8C/COqvrlMU7nAZK8ADiyqn47ybOA/1xVLxgacw1weFXNtfMbgEOr6hsDY54JHEW33fcWutWT1y2wHTo2PZjffsB+VXVlkkcCnweOqqovD4w5EjiRrf8+311VT0/yTrp/izcBb6+qFyU5Ebi7qs4d/rMmof29/1+6Grsnj+if2rkBJDkCeDewC/CBqnr7UP9udDWDPwN8A3hpVd2UZA3dzRb/Brysqra0GsMLgCMWa4t2R3/vTRvvApNGezxwcat5XQH8z6r6+PzKVlX9Md3q1pF0q1v3Aq+av3hgdeslrelsuhWgFWytK5mkNcAL2y+S3YG9kvx5Vb1iYMz8CtdckhXAo4BvzncOzPGldCslpwGr6Va7/us4JrENMz2/to18Wzu+J8lmuhWtLw8Mu79IH7isFXJvq0j/8HHOYVuq6h/mi9IXMLVzS/eZae+jWzmfA65IsnEweWWgPi3Jerr6tJeytT5tNd3PkddhfdoOMwGSRjid028Yanrrhmx46+mcDsCGbDhr/njAFRuyYf76+bZvbsgGhsZ+bn4cjH91C6CqTgVOBRhYIXnF0LCNwLHA/wJeDFw69EP2WOBvqupbbXvhB+018a2GWZ/foJYoPA24fKhr2j+CYlumeW6HAluq6kaAJH9Bl9ANJ6+nt+MLgfdan7b4TIAk3S/Jm4FNVbUROAc4L8kWupWR9QPj9qBLEH6xNb2Trnbru3RF8cvSrM0vySPo4jq5qu4e7h5xSVXVzcCz2vUHMlCkD6wE3lhV/7x0US+KaZ7bqOTt6QuNqar7kgzXp30HOIauVnJZ1adNE2uAtsMaoNGc3+KZ5bmB81sqSXYFPgZ8oqreOaL/T4DPVtX57fw64FlDd2FeQLfN92vAP9LVzryxql6+5BPYjray9bEFaoCmdm5JjqarPXt1Oz+GrvbsxIExE61P60sNUO/uAktyRJLr2t0Dp0w6Hkl6qNp2yDnA5lHJTzPNH0GxPdM8twdz9+j9Y7ZTn/YWtt5Z+ud09Wl6kHq1BfYgi88kablbQ7cF8sUkV7W2NwA/AtNfpJ/kfLqtrH2TzNH9gt8Vpn9uwBXAQUmeQPcA6fXArw6NmYn6tOWuV1tg7XMhTq+qw9v5qQBV9XvbuMYtsBGc3+KZ5bmB81tszm9xTWILs92deCbdbfB/WlVvG6xPS7I7cB5dcfs3gfUDRdN7AH8D/GJVfS/JzwF/RKtPW4wap75sgfVqBYgHV3wmSdKS2JANNXRX6PAdpsN3jT4RuGHEHabfHTH2uknfYTpN+rYCtN3is9Z+PDD/7KcnAdeNMcx9gYWePj4LnN/0muW5gfObds5v8fxoVT12TH/WxPRtBejBFJ9RVWfT7RuP3awvPTq/6TXLcwPnN+2cnx6qvt0Fdn/xWZKVdMVnGycckyRJGrNerQC1D5R6DfAJthafXTPhsCRJ0pj1KgECqKpL6G6hXK4msvU2Rs5ves3y3MD5TTvnp4ekV0XQkiRJ0L8aIEmSJBMgSZLUPyZAWhJJDkyyZkT7zyV54iRikvosyZok75t0HNJyYQKkpXImcM+I9u+0vpmUZN/2LKKZkeSxSWbqQ9GSvH7g+OihvjPGH9HSSPLUJO9IchPwVuDaCYe0KJL8yKRjWCpJ1iU5YeD88iQ3tteLJxnbrDEBWgaS/EqS65PcleTuJPckuXvSce2k1VV19XBjVW0CVo8/nMWX5LAkn01yUZKnJfkS8CXg9iRHTDq+ndGesn16kq/T/dL85yR3JnnTpGNbJOsHjk8d6pv29+7Hk7wpyWbgvXSP/0lVPbuq/seEw1ssfzV/kOQjkwxkCbyef//5dLsBP0v3cNjl8DDXmWECtDy8A3hhVT2qqvaqqkdW1V6TDmon7b6NvoePLYql9V7gDOB84FLg1VX1Q8AzgQUfsDslTqZ74vjPVtVjqmofuufmrUnyu5MNbVFkgeNR59PmWmAt8EtV9R9b0vP9Cce02Abfox+bWBRLY2VVDT6z8nNV9Y2quhnYc1JBzSIToOXh9qraPOkgFtkVSX59uDHJccDnJxDPUlhRVZ+sqr8EvlZVlwFU1SxsM7yS7snS/zLf0J5G/YrWN+1qgeNR59PmRcDXgM8keX+StUx/UjdsW+/ftNtn8KSqXjNwOlNb0ZPWuw9CXKY2JbmAbln33+Ybq+qiyYW0004GLk7ycrYmPIcAK4FfnlhUi+sHA8ffGeqb9h/Ku1bVAx68WFV3Jtl1EgEtsqe0beYADx/Ycg7bXr1c9qrqYrr/9vYEjgJ+F3h8krOAi6vqkxMNcHFs6/2rKV9BvzzJr1fV+wcbk/wG8L8nFNNM8oMQl4EkfzaiuarqP409mEWW5NnAk9vpNVV16STjWUxJvg98m/ZDGLh3vgvYvaqmNlFIcmVVHfxQ+7Q8JXk0cDTw0qp6zqTj0cKSPI6t/zN8ZWv+GbpaoKOq6vZJxTZrTIAkPcBAcveALqY8uZOmQZLnAD/VTmfqfx6XCxOgZSDJ7sBxdP/Y719+n4UVIEmSliOLoJeH84AfAg4H/h5YxejP0JEkSYvg/wO1tv6KCLOJHQAAAABJRU5ErkJggg=='></td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row10_col8" class="data row10 col8" >3/10 0.05 5%</td>
</tr>
<tr>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row11_col0" class="data row11 col0" >embark_town</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row11_col1" class="data row11 col1" >11</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row11_col2" class="data row11 col2" >category</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row11_col3" class="data row11 col3" >Where the passenger got on the ship (C - Cherbourg, S - Southampton, Q = Queenstown)</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row11_col4" class="data row11 col4" >2<br/> 0%</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row11_col5" class="data row11 col5" >4<br/> 0%</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row11_col6" class="data row11 col6" >Southampton 72%<br/> Cherbourg 19%<br/> Queenstown 9%<br/> nan 0%</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row11_col7" class="data row11 col7" ><img src='data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAkAAAACQCAYAAADgO9QwAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADl0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uIDMuMC4zLCBodHRwOi8vbWF0cGxvdGxpYi5vcmcvnQurowAAD8xJREFUeJzt3X2wXVV9h/HnCwEEFIO8WA0oWCJKEUdkIowttWVUoGisCoIMpoiNbVFh1JZUhQx0tGXsaGXqYCNogzIoRSyhZUopqGgVhosiLwYk0goRBC2I1mgh+OsfewUO1xsIIfeee85+PjN37t7rrH3y27Nzc7/Za529UlVIkiT1yWbDLkCSJGmmGYAkSVLvGIAkSVLvGIAkSVLvGIAkSVLvGIAkSVLvGIAkSVLvGIAkSVLvGIAkSVLvGIAkSVLvGIAkSVLvGIAkSVLvGIAkSVLvGIBmoSR7Jrlu4OunSU5M8uEkNye5PskXk8xdz/EHJ7klyaokSwbaz23Hfmig7eQkC2fivCRJmi1SVcOuQY8hyebAD4CXAXsCV1TV2iSnA1TVSVP0/y7wSmA1cA1wFDAHOKmqjk7yVeAwYBtgWVW9ZqbOR5Kk2cA7QLPfQcD3qur7VfXvVbW2tV8F7DJF/wXAqqq6raoeAD4HLAQeBLZOshmwJfAQcBpwyrSfgSRJs4x3gB5Hkh8B3x9iCbsBPwd+NKl9D+De9jVoe2A7Hqn5GcBTgduBXYGnAf8D/BTYmeGemyRp9nluVe007CKm25xhFzACvl9V+w3jD06yJXAnsKCq7h5ofz+wH/D6mpRgkxwOvLqq3tb2j2nHv3NSv4vphsmOBV4MXFZVn5zO85EkzX5JJoZdw0xwCGx2OwT45qTws4hu/s7Rk8NPs5ruTs86u9CFqIe1Sc8TwLbA3lV1BHBMkm02cf2SJM1KBqDZ7SjgvHU7SQ4GTgJeW1Vr1nPMNcD8JLu3O0hHAisG3mML4ATgw3SToNeFqHVzgyRJGnsGoFmq3Y15JXDhQPPf083huax9PP4Tre+zk1wC0CZJvwO4FFgJnF9VNw28x/HA8hagru8Ozw3Af1bVT6b7vCRJmg2cBP04kkzM5BygU3PqWF+QpbU0w65BkrR+M/17b1i8AyRJknrHACRJknrHACRJknpn5ANQkrlJLmhrZK1MckCSZyS5LMmt7fv2rW+SnNHWyLo+yb7Drl+SJM28kQ9AwMeAf6uqF9A90G8lsAS4vKrmA5e3feieqzO/fS0Gzpz5ciVJ0rCNdABKsh1wIHA2QFU90D7KvRBY3rotB17XthcC51TnKmBukmfNcNmSJGnIRjoAAc+jWyPr00m+leSsJNsCz6yquwDa951b/3nAHQPHr25tkiSpR0Y9AM0B9gXOrKqX0C0auuQx+k/1DJpfe+5OksVJJtp6KDtukkolSdKsMeoBaDWwuqqubvsX0AWiu9cNbbXv9wz0f8x1sgCqallV7dceBPXj6SpekiQNx0gHoKr6IXBHkj1b00HAd+jWvlrU2hYBF7XtFcBb2qfB9gfuXzdUJkmS+mPOsAvYBN4JnNsW/rwNOJYu2J2f5DjgduDw1vcS4FBgFbCm9ZUkST0z8gGoqq4Dplqz5KAp+hbdYqCSJKnHRnoITJIkaWMYgCRJUu8YgCRJUu8YgCRJUu8YgCRJUu8YgCRJUu8YgCRJUu8YgCRJUu8YgCRJUu8YgCRJUu8YgCRJUu8YgCRJUu8YgCRJUu8YgCRJUu8YgCRJUu8YgCRJUu8YgCRJUu8YgCRJUu8YgCRJUu8YgCRJUu8YgCRJUu8YgCRJUu8YgCRJUu+MRQBKsnmSbyX5l7a/e5Krk9ya5PNJtmztW7X9Ve313YZZtyRJGo6xCEDACcDKgf3TgY9W1XzgPuC41n4ccF9V7QF8tPWTJEk9M/IBKMkuwB8AZ7X9AL8PXNC6LAde17YXtn3a6we1/pIkqUdGPgABfwf8BfCrtr8D8JOqWtv2VwPz2vY84A6A9vr9rb8kSeqRkQ5ASQ4D7qmqawebp+haG/Da4PsuTjKRZALY8clXKkmSZpM5wy7gSXo58NokhwJPAbajuyM0N8mcdpdnF+DO1n81sCuwOskc4OnAvZPftKqWAcsAWgiSJEljZKTvAFXVX1bVLlW1G3AkcEVVHQ18CXhj67YIuKhtr2j7tNevqKpfuwMkSZLG20gHoMdwEvDuJKvo5vic3drPBnZo7e8GlgypPkmSNESjPgT2sKr6MvDltn0bsGCKPr8EDp/RwiRJ0qwzrneAJEmS1ssAJEmSescAJEmSescAJEmSescAJEmSescAJEmSescAJEmSescAJEmSescAJEmSescAJEmSescAJEmSescAJEmSescAJEmSescAJEmSescAJEmSescAJEmSescAJEmSescAJEmSescAJEmSescAJEmSescAJEmSescAJEmSescAJEmSemekA1CSXZN8KcnKJDclOaG1PyPJZUlubd+3b+1JckaSVUmuT7LvcM9AkiQNw0gHIGAt8J6qeiGwP3B8kr2AJcDlVTUfuLztAxwCzG9fi4EzZ75kjbskn0pyT5IbB9penOQbSW5IcnGS7dZz7MFJbmkhfclA+7kttH9ooO3kJAun92wkaTyNdACqqruq6ptt+2fASmAesBBY3rotB17XthcC51TnKmBukmfNcNkaf/8IHDyp7SxgSVW9CPgi8OeTD0qyOfBxuqC+F3BUkr2S7ANQVfsAv5Pk6e3v7YKqumj6TkOSxtdIB6BBSXYDXgJcDTyzqu6CLiQBO7du84A7Bg5b3dqkTaaqrgTundS8J3Bl274MeMMUhy4AVlXVbVX1APA5utD+ILB1ks2ALYGHgNOAU6ahfEnqhbEIQEmeCnwBOLGqfvpYXadoqyneb3GSiSQTwI6bqEz1243Aa9v24cCuU/SZMqBX1UrgduCbwPnAHkCq6lvTV64kjbc5wy7gyUqyBV34ObeqLmzNdyd5VlXd1YYK7mntq3n0L55dgDsnv2dVLQOWtfefmLbi1SdvBc5IcgqwAnhgij7rDehVdeLDnZKLgbcneT/wYuCyqvrkpi9ZksbXSN8BShLgbGBlVX1k4KUVwKK2vQi4aKD9Le3TYPsD968bKpOmU1XdXFWvqqqXAucB35ui2+MG9DbpeQLYFti7qo4AjkmyzfRULknjadTvAL0cOAa4Icl1re19wN8A5yc5jm7o4PD22iXAocAqYA1w7MyWq75KsnNV3dPm8XwA+MQU3a4B5ifZHfgBcCTw5oH32AI4ATiM7pOM64Zv180NWjN9ZyBJ42WkA1BVfY2phw0ADpqifwHHT2tR6r0k5wGvAHZMshpYCjw1ybq/excCn259nw2cVVWHVtXaJO8ALgU2Bz5VVTcNvPXxwPKqWpPk+u7w3ABcUlU/mZGTk6QxkS4TaH2STFTVfjP1552aU8f6giytpesLrGNhnK/fuF87SZ2Z/r03LCM9B0iSJGljGIAkSVLvGIAkSVLvGIAkSVLvGIAkSVLvGIAkSVLvGIAkaUCSE5LcmOSmJCdO8XqSnJFkVZLrk+zb2vdMcm2Sbyc5oLXNSfIfPqlbmn0MQJLUJNkb+GNgAd06a4clmT+p2yF0T+KeDywGzmztbweWAG8E3tva/hT4TFX5lG5pljEASdIjXghcVVVrqmot8BXgDyf1WQicU52rgLlt0eUHga2BbYAHk8wFXgOcM3PlS9pQI70UhiRtYjcCH0yyA/ALurUDJyb1mQfcMbC/urV9nC7sbEV3N+gU4IPl4/alWckAJElNVa1McjpwGfC/wLeBtZO6TbUkSFXV7XRrwJFkD+DZwM1JPkO3WO3JVfXd6apd0hPjEJgkDaiqs6tq36o6ELgXuHVSl9XArgP7uwB3TurzQeBk4F3AuXQL4i6dnoolbQwDkCQNSLJz+/4c4PXAeZO6rADe0j4Ntj9wf1XdNXD87wI/qKpb6eYD/Qp4qG1LmiUcApOkR/tCmwP0IHB8Vd2X5E8AquoTwCV0c4NWAWuAY9cdmCTAB4AjWtMyujtAc+g+ESZplojz8x5bkomq2m+m/rxTc+pYX5CltXSq+RNjY5yvn9dutI379dOmM9O/94bFITBJktQ7BiBJktQ7BiBJktQ7BiBJ0lhIcnCSW9o6bUumeH2rJJ9vr1+dZLfW/vK2rts17RlOJJmb5NI2sV1jyAAkSRp5STanexr3IcBewFFJ9prU7TjgvqraA/gocHprfw/wBuB9PPJpvZOBD/kk7/FlAJIkjYMFwKqquq2qHgA+R7du26CFwPK2fQFwULvDM3kdt98E5lXVV2amdA2DzwGSJI2DqdZoe9n6+lTV2iT3AzsAf033zKZfAMcAf0t3B0hjrHd3gB5vjFiSNJKmXKNtQ/pU1XVVtX9V/R7wPLqlTdLmC302yTM3dbEavl4FoA0cI5YkjZ4NWaPt4T5J5gBPp1vvjda27knef8Uj67d9lm5NN42ZXgUgNmyMWJI0eq4B5ifZPcmWwJF067YNWgEsattvBK6YNMl5EfCvVXUfj6zj9itcx20s9W0O0IaMEUuSRkyb0/MO4FJgc+BTVXVTktOAiapaAZwNfCbJKro7P0euOz7JNnQB6FWt6SPAF4AHgKNm7kw0U3q1FliSw4FXV9Xb2v4xwIKqeuekfouBxW13T+CWGS10Zu0I/HjYRWijeO1Gm9dvtI3z9XtuVe007CKmW9/uAG3IGDFVtYzuEwFjry+L3o0jr91o8/qNNq/f6OvbHKANGSOWJEljrld3gNY3RjzksiRJ0gzrVQACqKpLgEuGXccs0ouhvjHltRttXr/R5vUbcb2aBC1JkgT9mwMkSZJkAJIkSf1jAJIkSb3Tu0nQgiTzgOcycP2r6srhVST1Q5KtgDcAu/Hon7/ThlWT1FcGoJ5JcjrwJuA7wEOtuQAD0AhIcjG/vsL1/cAE8A9V9cuZr0pPwEV01+ta4P+GXIuegCSvB04HdqZbVT50K8lvN9TCtNH8FFjPJLkF2Keq/Md3BCX5GLATcF5rehPwQ2BrYLuqOmZYtenxJbmxqvYedh164tr6Ya+pqpXDrkWbhneA+uc2YAv83+eoeklVHTiwf3GSK6vqwCQ+1HP2+3qSF1XVDcMuRE/Y3Yaf8WIA6p81wHVJLmcgBFXVu4ZXkp6AnZI8p6puB0jyHLpFGaFbtVqz228Df5Tkv+h+/tYNo+wz3LK0ASaSfB74Zx79b+eFwytJT4YBqH9W4Ppno+w9wNeSfI/ul+fuwJ8l2RZYPtTKtCEOGXYB2mjb0f0H8lUDbQUYgEaUc4B6qC0E+/y2e0tVPTjMerRhkmwG7E83gfYFdAHoZic+j44kpwFfBb5eVT8fdj1SnxmAeibJK+juFPw33S/QXYFFfgx+NCT5RlUdMOw6tHGSvJVuGOwA4Gd0YejKqrpoqIXpcSV5CnAc8FvAU9a1V9Vbh1aUnhQDUM8kuRZ4c1Xd0vafD5xXVS8dbmXaEElOBa4HLix/eEdWkt8AjgDeC2xfVU8bckl6HEn+CbgZeDNwGnA0sLKqThhqYdpo/w/Mh5Bg4JBtQwAAAABJRU5ErkJggg=='></td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row11_col8" class="data row11 col8" >5/10 0.03 3%</td>
</tr>
<tr>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row12_col0" class="data row12 col0" >alone</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row12_col1" class="data row12 col1" >12</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row12_col2" class="data row12 col2" >bool</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row12_col3" class="data row12 col3" ></td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row12_col4" class="data row12 col4" >0<br/> 0%</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row12_col5" class="data row12 col5" >2<br/> 0%</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row12_col6" class="data row12 col6" >True 60%<br/> False 40%</td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row12_col7" class="data row12 col7" ><img src='data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAkAAAACQCAYAAADgO9QwAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADl0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uIDMuMC4zLCBodHRwOi8vbWF0cGxvdGxpYi5vcmcvnQurowAACyNJREFUeJzt3X+sX3V9x/Hni1YqZnOAgMG2SDcbHUtkkKbSmCxTEkFllD9GBtlmZ1iaDWY0LDpcHCYoy5b9UDFzS5UlbaJjBLa0WQikq7rEJTALuCF2rg0btinCGD80w/Gr7/3x/Vzypf3y097vud/v5/lIbu75fM7nnLxPc8+9r57P+dybqkKSJKknxwxdgCRJ0rQZgCRJUncMQJIkqTsGIEmS1B0DkCRJ6o4BSJIkdccAJEmSumMAkiRJ3TEASZKk7hiAJElSdwxAkiSpOwYgSZLUHQOQJEnqjgFIACQ5PslNSf49yZ4kG5KcmGRnkr3t8wkvcOymNmZvkk2tb0WSW5N8O8nlY2O3JDlrWtclSdIkBiAt+Bxwa1W9DTgT2ANcBeyqqrXArtZ+niQnAp8E3gGsBz7ZgtJ5wJ3A24HNbeyZwDFVdffiX44kSS/MACSSvB74BeB6gKp6qqoeAzYCW9uwrcBFEw4/D9hZVY9U1aPATuB84GngOGD52NhPAVcvykVIkvQKpKqGrmFJS/LfwP1D17HIjgNOB34EvA74X2A/o6c33xob9/OHtQHeyChIP9DapwKHgAeBNe3c3weebed+AEnSUvbmqjp56CIW2/KXHtK9+6tq3dBFLKYk64DbgXdX1R1JPgf8APjp8WtP8ujh/xZJPgqsqKpPt/YfAE9U1Z+NjXkNcBtwIXANcBqwrap2LPKlSZJeoSS7h65hGpwCE8AB4EBV3dHaNwFnAw8mORWgfX7oBY5dPdZeBRw8bMzljKbQNgBPAb8CfOKoVS9J0itkABJV9X1gf5K3tq5zge8AO4BNrW8TsH3C4bcB70lyQnv5+T2tD4DWdwGwjdEU2CGggNcuwqVIkvSyOAWmBR8CvpzkWOA+4IOMAvKNSS4DvgdcDM9Nmf1WVf1mVT2S5FPAN9t5rqmqR8bOezXw6aqqJLcBVwD3AH81lauSJGkCX4J+CUl2z/M7QAl+AcyoKjJ0DZLmz7z/3FvgFJgkSeqOAUiSJHXHACRJkrpjAJIkSd0xAEmSpO4YgCRJUncMQJIkqTsGIEmS1B0DkCRJ6o4BSJIkdccAJEmSumMAkiRJ3TEASZKk7hiAJElSdwxAkiSpOwYgSZLUHQOQJEnqjgFIkiR1xwAkSZK6YwCSJEndMQBJkqTuGIAkSVJ35iIAJVmW5O4k/9Daa5LckWRvkr9NcmzrX9Ha+9r+04esW5IkDWMuAhDwYWDPWPuPgc9U1VrgUeCy1n8Z8GhVvQX4TBsnSZI6M/MBKMkq4P3Al1o7wLuBm9qQrcBFbXtja9P2n9vGS5Kkjsx8AAI+C3wMONTabwAeq6pnWvsAsLJtrwT2A7T9j7fxkiSpIzMdgJJcADxUVXeOd08YWi9j3/h5NyfZnWQ3cNKPX6kkSVpKZjoAAe8ELkzyX8ANjKa+Pgscn2R5G7MKONi2DwCrAdr+nwIeOfykVbWlqtZV1Trg4UW9Aklde7mLOCYc9/G2oOO7Sc5rfScn+UaSbye5aGzs9iRvms4VSbNhpgNQVX28qlZV1enAJcBXq+pXga8Bv9yGbQK2t+0drU3b/9WqOuIJkCRN0ctdxPGcJGcw+p73c8D5wBeSLAMuZfSe4wbgo23sLwF3VdXBw88j9WymA9CL+D3gyiT7GL3jc33rvx54Q+u/ErhqoPok6ZUu4hi3Ebihqp6sqv8E9gHrgaeB44AVwKH2pPsjwJ8s5nVIs2j5Sw+ZDVX1deDrbfs+Rt8MDh/zf8DFUy1Mkl7YwiKOn2ztF1vEMW4lcPtYe2HcV9rHBxj9R/ByYFtVPXH0S5dm27w+AZKkJe1VLOJ43uGTxlXV41X1/vb+4l3ABcDNSb6Y5KYkG378yqX5MDdPgCRpxiws4ngf8Frg9Ywt4mhPgcYXcYx7bkFHM2nc1cC1jN4LupPRk6HtwLuO5kVIs8onQJI0gFexiGPcDuCS9ud91gBrgX9Z2JlkLfCmqvon4HWMfk9aMQpakjAASdJSM3ERR5ILk1wDUFX3AjcC3wFuBa6oqmfHznEt8Im2/TfAbzB6Z+hPp3EB0iyIq8BfXJLdbT59LiUT3y/QDKia+B6IZoT33myb5/tv3n/uLfAJkCRJ6o4BSJIkdccAJEmSumMAkiRJ3TEASZKk7hiAJElSdwxAkiSpOwYgSZLUHQOQJEnqjgFIkiR1xwAkSZK6YwCSJEndMQBJkqTuGIAkSVJ3DECSJKk7BiBJktQdA5AkSeqOAUiSJHXHACRJkrpjAJIkSd0xAEmSpO4YgCRJUncMQJIkqTsGIEmS1J2ZDkBJVif5WpI9Se5N8uHWf2KSnUn2ts8ntP4kuS7JviT/luTsYa9AkiQNYaYDEPAM8LtV9bPAOcAVSc4ArgJ2VdVaYFdrA7wXWNs+NgN/Of2SJUnS0GY6AFXVA1V1V9v+IbAHWAlsBLa2YVuBi9r2RmBbjdwOHJ/k1CmXLUmSBjbTAWhcktOBs4A7gDdW1QMwCknAKW3YSmD/2GEHWp8kSerI8qELOBqS/ARwM/CRqvpBkhccOqGvJpxvM6MpMoCTjkqRkiRpyZj5J0BJXsMo/Hy5qv6udT+4MLXVPj/U+g8Aq8cOXwUcPPycVbWlqtZV1Trg4UUrXpIkDWKmA1BGj3quB/ZU1Z+P7doBbGrbm4DtY/0faKvBzgEeX5gqkyRJ/Zj1KbB3Ar8O3JPkW63v94E/Am5MchnwPeDitu8W4H3APuAJ4IPTLVeSJC0FqTriFRiNSbK7TYXNpeTId6A0G6omvtOmGeG9N9vm+f6b9597C2Z6CkySJOnVMABJkqTuGIAkSVJ3DECSJKk7BiBJktQdA5AkSeqOAUiSJHXHACRJkrpjAJIkSd0xAEmSpO4YgCRJUncMQJIkqTsGIEmS1B0DkCRJ6o4BSJIkdccAJEmSumMAkiRJ3TEASZKk7hiAJElSdwxAkiSpOwYgSZLUHQOQJEnqjgFIkiR1xwAkSZK6YwCSJEndMQBJkqTuGIAkSVJ3DECSJKk7BiBJktQdA5AkSepOdwEoyflJvptkX5Krhq5HkiRNX1cBKMky4C+A9wJnAJcmOWPYqiRJ0rR1FYCA9cC+qrqvqp4CbgA2DlyTJEmast4C0Epg/1j7QOuTJEkdWT50AVOWCX11xKBkM7C5Nd+aZPeiVjWsO4cuYJGdBDw8dBGLIWGevy574L03w+b8/nvz0AVMQ28B6ACweqy9Cjh4+KCq2gJsmVZRWjxJdlfVuqHrkHrjvaelrrcpsG8Ca5OsSXIscAmwY+CaJEnSlHX1BKiqnknyO8BtwDLgr6vq3oHLkiRJU9ZVAAKoqluAW4auQ1PjVKY0DO89LWmpOuIdYEmSpLnW2ztAkiRJBiBJktQfA5DmUpIVQ9cgSVq6DECaK0nWJ7kH2NvaZyb5/MBlSV3IyK8lubq1T0uyfui6pEkMQJo31wEXAP8DUFX/Crxr0IqkfnwB2ABc2to/ZPQHqKUlp7tl8Jp7x1TV/cnz/urJs0MVI3XmHVV1dpK7Aarq0fZLZ6UlxwCkebO/PXKvJMuADwH/MXBNUi+ebvddASQ5GTg0bEnSZE6Bad78NnAlcBrwIHBO65O0+K4D/h44Jcm1wDeAPxy2JGkyfxGiJOmoSfI24FwgwK6q2jNwSdJEBiDNlSRfpD1+H1dVmwcoR+pKkp8BDlTVk0l+EXg7sK2qHhu2MulIToFp3vwjsKt9/DNwCvDkoBVJ/bgZeDbJW4AvAWuArwxbkjSZT4A015IcA+ysqnOHrkWad0nuaqvAPgb8qKo+n+Tuqjpr6Nqkw/0/pse5jYn7bbMAAAAASUVORK5CYII='></td>
<td id="T_069198c8_cfa6_11e9_9138_5c5f67a418f1row12_col8" class="data row12 col8" >10/10 0.01 2%</td>
</tr>
</tbody></table>
That’s All!
Feel free to leave any feedback!