Installation
!pip install TEF -U
import TEF
TEF.__version__
'0.7.7'
!pip install TEF -U
import TEF
TEF.__version__
'0.7.7'So I finally decided to upgrade my Surface Pro 4 (M3), bought in 2018. This time, I chose the highest trim – i7 with 32 GB RAM. Obviously, not every product is perfect and since this is not a cheap purchase, I thought people might be interested to see some real review. Here it is.

import pandas as pd
train_transaction_raw = pd.read_csv('data/ieee-fraud-detection.zip Folder/train_transaction.csv')
import TEF
train_transaction = TEF.auto_set_dtypes(train_transaction_raw, set_object=[0])
TEF.dfmeta(train_transaction)
TEF.plot_1var(train_transaction)
TEF.plot_1var_by_cat_y(train_transaction, 'isFraud')
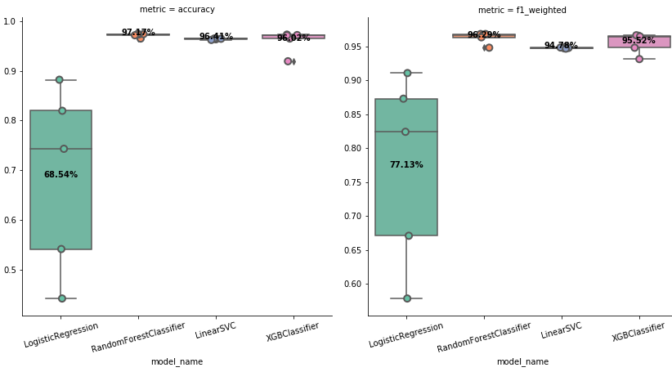
TEF.fit(train_transaction, 'isFraud', verbose=2)
Disclaimer and Caveat
Every ML practitioner knows it is a risky behavior to fit a model without understanding the data. The purpose of this article is to introduce the universal usage of TEF only instead of detailed exploration. Within these code, we can only have a rough understanding about the dataset.
In the following section I will walk through these codes for this ieee fraud detection dataset. A more detailed exploration, feature engineering, and model selection may be published in the future.
Continue reading How To Fit A Machine Learning Model To A Kaggle Dataset In 8 LinesThis is a list of my featured articles. Some are abstracted below. If you want a translated version, please don’t hesitate to contact me.
For your reference, I was 20 years old (sophomore) at 2014, 16 at 2010.
This report is aimed to answer the following two questions. 1. Does the use of swear words have any regiospecificity that result in heterogeneous in the data? 2. Does the use of swear words in customers’ review have an impact on the ratings they gave? Can it predict the stars they gave toward a business? Mainly, analysis using ANOVA on metropolis, multiple regression on ratings are performed. Results indicate that the usage of swear words is different by region and 25 of 45 swear words have predictability on the rating a customer gave. All code and files can be obtained from the link in the end.
Continue reading Swear Words in Review: Regiospecificity and Predictability